Figure 1 - A single module with multiple responsibilities
")
Some people think that I am saying that Dependency Injection is evil under all circumstances - this is not true.
Some people think that I am suggesting an alternative to Dependency Injection - this is not true (unless you include NOT injecting dependencies).
Some people say that my implementation of Dependency Injection has been proven to be ineffective - this is not true.
Disco with Design Patterns: A Fresh Look at Dependency Injection
Way back in 2004 I made the following observation:
There are two ways in which an idea, principle or rule can be implemented - indiscriminately or intelligently.
Every idea, principle or rule is always devised to cover a particular set of circumstances, and in those circumstances its implementation is supposed to provide some sort of measurable benefit. There has to be some reason to follow that principle otherwise its existence cannot be justified. This also implies that the converse is also true - when the principle is implemented in a different set of circumstances then those same benefits may not appear at all, or may even be replaced with a new set of disadvantages. Whenever I see a principle being promoted or encouraged I always ask the same questions:
Ask any programmer to describe the purpose of Dependency Injection (DI) and they will probably echo one of the following:
In software engineering, dependency injection is a programming technique in which an object or function receives other objects or functions that it requires, as opposed to creating them internally. Dependency injection aims to separate the concerns of constructing objects and using them, leading to loosely coupled programs.
Dependency injection (DI) is a programming technique that separates the construction of objects from their use. Objects get the objects they need from an outside source instead of creating them themselves.
Dependency injection is a technique used in object-oriented programming (OOP) to reduce the hard coded dependencies between objects.
Dependency injection is a programming technique that makes a class independent of its dependencies. It achieves that by decoupling the usage of an object from its creation.
This is not correct. This is a description of how it does it, but not why it does it. Its true purpose is to provide a means to take advantage of polymorphism where multiple objects share the same method signature(s) but with different implementations. This allows another object to call one of those methods without knowing the identity of that dependent object. Instead of being tightly coupled to a single dependent object it is loosely coupled to a collection of interchangeable objects. As an example let's say that we have an object A which calls a method M which exists in several classes C1 to C99. This means that object A can call method M on any one of the 99 versions of object C. It would be very wasteful to have those 99 calls hard-coded, so by using DI you can code the call just once on an object which is chosen outside of object A. This also means that you can create even more versions of object C without having to make any modifications to object A. The identity of the dependent object is chosen outside of the calling object and then injected into it, and that object then calls that method on whatever dependent object it has been given. In this way the calling object can be reused with a variety of different dependent objects.
The true purpose of DI is therefore not to separate a dependent object's instantiation from its use, but to provide a mechanism which allows the dependent object to be switched to one of a number of alternatives which share the same method signature. It should therefore follow that if a particular dependency does not have any alternatives then providing a mechanism to switch between alternatives which don't exist would be a complete waste of time.
Unfortunately many of today's programmers are being taught to use DI for every dependency even when there is no need to switch to an alternative object with a different implementation. You should be aware that the idea of providing a facility in your code which you will never actually use is a violation of YAGNI (You, Ain't Gonna Need It).
I recently came across an article called Learning About Dependency Injection and PHP in the Zend Developer Zone, and several phrases particularly caught my eye:
In any circle of developers that are of the object-oriented persuasion, you'll never hear an argument that dependency injection itself, is bad. In these circles, it is generally accepted that injecting dependencies is the best way to go.
This was closely followed by:
The heart of the argument is not should we be doing it (Dependency Injection), but how do we go about doing it.
Those statements imply that if you are not using Dependency Injection (DI) then you are not doing OO "properly", that you are an idiot. I take great exception to that arrogant, condescending attitude. Design patterns are an option, not a requirement. Some OO programmers attempt to go a step further by saying that not only *must* you use their favourite selection of design patterns, but you *must* also adhere to their particular method of implementation.
Nowhere in his article does he explain the circumstances where DI can provide benefits, which means that he has no idea on the effects of DI when those circumstances do not exist. If you read the original description of this principle you should see where the author, Robert C. Martin (Uncle Bob), provided an example with his "Copy" program. This program has to deal with any number of different devices which support the reading and writing of data so that data can be copied from one device to another. Each device requires different code to implement the read() and write() operations, so each device has its own object which implements those operations. When the "Copy" program is activated the relevant device objects are injected into it so that it can call the read() method on the input object and the write() method on the output object without concerning itself with how those methods are actually implemented. It should be obvious from this example that the ability to inject a dependency into an object was designed for the circumstances where there is a choice of multiple dependent objects which can be injected. It should therefore follow that when there is only a single choice then the ability to deal with multiple choices is wasted and is therefore a violation of the YAGNI principle.
Those among you who are observant should notice that in this description of the "Copy" program that there can be any number of different device objects which can be used either as the input device or the output device. Each of these objects must therefore have implementations of both the read() and write() methods, which is a perfect example of Polymorphism. It should then be obvious that you cannot implement DI unless you have a collection of objects with the same polymorphic methods. You should also observe that the device objects are examples of entity objects while the "Copy" program is an example of a service object. These terms are explained below in Object Types.
When a principle is encapsulated in a design pattern too many programmers think that because it exists then it must be implemented even when it is not appropriate as they do not have the mental ability to judge whether their circumstances are appropriate or not. These people are known as pattern junkies because of their indiscriminate use of patterns. I am not one of these people as I can work out for myself whether a particular pattern is appropriate for my circumstances or not, and I only use a pattern when its benefits are clearly obvious. Not only will I decide *if* I use a particular pattern in the first place, I will also decide *how* it should be implemented. Because I do not follow the crowd and prefer to think for myself I am widely regarded as being a maverick, a heretic and an outcast by those who consider themselves to be "proper" OO programmers. If you think you have the stomach for it you can read some of my controversial views in the following articles:
I could not let the arrogant statements in Ralph's article pass without comment, so I posted a reply. This was initially passed by the moderator, but was removed 24 hours later. It seems that some OO "purist" objected most strongly to my heretical viewpoint and had my comment removed. This I take as a form of censorship and a violation of my right to free speech. The OO Nazis may think that they have silenced my heretical viewpoint, but they are not the only ones who can publish articles on the internet! Below is my original response to Ralph's article:
This article is yet another glaring example of where OO programmers deliberately try to make a mountain out of a molehill just to prove how clever they are. To me it proves just the opposite.In my long career in software development I have learned to follow a number of key principles:
- If it ain't broke don't fix it.
- If it doesn't cause a problem it doesn't need a solution.
- Keep It Simple, Stupid!
This "solution" is supposed to address the problem of dependencies, but what exactly is the problem? You cannot eliminate dependencies altogether as your software just would not work. If module A needs to perform some processing which is already contained within Module B then Module A simply calls Module B. This may create a dependency, but so what? It's certainly better than having the code within Module B duplicated within Module A. This is what "Modular Programming" is all about, and Object Oriented Programming is supposed to be an extension of this paradigm by using "objects" instead of "modules".
The idea that you need to "manage" dependencies is also ridiculous. If I have the following code in Module A:
$objectB = singleton::getInstance('classB'); $result = $objectB->doStuff(...);it is simple to understand and easy to modify. So why change to a different method which is less simple? What are the costs? What are the benefits? By introducing another layer of management you are moving towards the situation where there are too many chiefs and not enough Indians. Your application will contain a small amount of code which does useful work and a large amount of code which manages the workers. It will take longer and longer to get things done, and longer and longer to adapt to changes. And you call this "progress"? Pull the other one, it's got bells on!
There's a saying in the world of aviation:
There are old pilots and there are bold pilots, but there are no old bold pilotsIn the world of software development we now have:
There are sensible programmers and there are OO programmers, but there are no sensible OO programmersWhen you say that "injecting dependencies is the best way to go" you forgot to add "in cloud cuckoo land". Those of us who have to live in the "real" world will continue to ignore such ridiculous concepts while still being able to write effective software.
It is supposed to be "good practice" to do the following things:
Both of these principles, which are supposed to be "good", result in the creation of dependencies which we are now told are actually "bad". This contradiction makes me believe that one of those statements is downright wrong, so I will follow my instincts (and decades of programming experience) and continue to write modular and layered software with lots of dependencies and no dependency management (except in those places where it provides measurable benefits).
I shall now follow with a more detailed critique of this abominable pattern.
It is pointless using a term unless you define precisely what that term means to you. Others may have different definitions (WHY??) so that a statement which seems perfectly obvious to you could be confusing to someone else.
This wikipedia article defines "dependency" as follows:
In computer science dependency, or coupling, is a state in which one object uses a function of another object.
Note here that "dependency" and "coupling" are interchangeable, they mean exactly the same thing. This means that the idea that you can de-couple a dependency is absolute nonsense. You can make the coupling either loose or tight, but you cannot remove it without destroying the dependency.
This wikipedia article offers a more detailed definition:
In software engineering, coupling is the manner and degree of interdependence between software modules; a measure of how closely connected two routines or modules are; the strength of the relationships between modules.
Coupling is usually contrasted with cohesion. Low coupling often correlates with high cohesion, and vice versa. Low coupling is often a sign of a well-structured computer system and a good design, and when combined with high cohesion, supports the general goals of high readability and maintainability.
As an example, let us take two modules: ModuleA and ModuleB. If ModuleA contains a call to ModuleB then this results in the following:
The term dependency is often interchangeable with coupling. Because there now exists a dependency between ModuleA and ModuleB, they are effectively coupled in a relationship. This coupling is either tight or loose where loose coupling is supposed to be better.
If two modules have a relationship due to the existence of a dependency between them, then they are said to be coupled by this relationship. If there is no relationship between two modules, no dependency between them, then they are not coupled. Coupling describes how the modules interact; the degree of mutual interdependence between the two modules; the degree of interaction between two modules. Coupling can either be low/loose/weak or high/tight/strong. Loose coupling is supposed to be better. Coupling is usually contrasted with cohesion.
Note that the number of connections between modules also has a bearing on the maintainability of the code as well as the simplicity of each connection. Some people seem to think that "de-coupling", where a direct call between two modules is interrupted by inserting a call to an intermediate object, is a good idea. This is not correct as it has the effect of doubling the number of connections which makes the path through the code more convoluted that it need be. The shortest distance between two points is a straight line, so if you interrupt the line with more points and change direction between them you can easily loose sight of where you came from and where you are going.
Tightly coupled systems tend to exhibit the following developmental characteristics, which are often seen as disadvantages:
In this wikipedia article there is a description of tight coupling:
Content coupling (high)
Content coupling (also known as Pathological coupling) occurs when one module modifies or relies on the internal workings of another module (e.g., accessing local data of another module). Therefore changing the way the second module produces data (location, type, timing) will lead to changing the dependent module.
Here is an example of tight coupling:
<?php $dbobject = new Person(); $dbobject->setUserID ( $_POST['userID'] ); $dbobject->setEmail ( $_POST['email'] ); $dbobject->setFirstname ( $_POST['firstname']); $dbobject->setLastname ( $_POST['lastname'] ); $dbobject->setAddress1 ( $_POST['address1'] ); $dbobject->setAddress2 ( $_POST['address2'] ); $dbobject->setCity ( $_POST['city'] ); $dbobject->setProvince ( $_POST['province'] ); $dbobject->setCountry ( $_POST['country'] ); if ($dbobject->insertPerson($db) !== true) { // do error handling } ?>
The above code exists within the consuming object and "Person" represents the dependent object. This is "tight" coupling because of the following:
Tight coupling often correlates with low cohesion.
Loosely coupled systems tend to exhibit the following developmental characteristics, which are often seen as advantages:
In this wikipedia article there is a description of loose coupling:
Message coupling (low)
This is the loosest type of coupling. It can be achieved by state decentralization (as in objects) and component communication is done via parameters or message passing.
In the same article it also states
Low coupling refers to a relationship in which one module interacts with another module through a simple and stable interface and does not need to be concerned with the other module's internal implementation.
Here is an example of loose coupling:
<?php require_once 'classes/$table_id.class.inc'; // $table_id is provided by the previous script $dbobject = new $table_id; $result = $dbobject->updateRecord($_POST); if ($dbobject->errors) { // do error handling } ?>
This has the following differences when compared with the tight coupling example:
$table_id.Loose coupling often correlates with high cohesion.
This wikipedia article contains the following statement:
Dependency injection aims to separate the concerns of constructing objects and using them, leading to loosely coupled programs.
This statement is ass-backwards. It is completely wrong to say that dependency injection leads to loose coupling
when in reality you must have loose coupling BEFORE you can implement dependency injection. As I explain in The true purpose of Dependency Injection the correct way to link DI and loose coupling goes in the following order:
It should be obvious that if different objects do similar things but with different method signatures due to tight coupling that there is no polymorphism and therefore no way to inject any dependencies.
Another explanation can be found in The difference between Tight and Loose Coupling.
The following definition was obtain from this wikipedia article.
In computer programming, cohesion refers to the degree to which the elements of a module belong together.
Cohesion describes the contents of a module, the degree to which the responsibilities of a single module form a meaningful unit, and the degree of interaction within a module. This relates to how well the Single Responsibility Principle (SRP) has been applied so that instead of a single "God" class which does everything you break it down in separate classes where each class does just one thing.
Cohesion can either be low/loose/weak or high/tight/strong. High cohesion is supposed to be better. Cohesion is usually contrasted with coupling.
Low cohesion implies that a given module performs tasks which are not very related to each other and hence can create problems as the module becomes large. Low cohesion in a module is associated with undesirable traits such as being difficult to maintain, test, reuse, and even understand. Low cohesion often correlates with tight coupling.
Here is an example of low cohesion:
A computer program usually has pieces of code which deal with different areas - user interface (UI) logic, business logic, and data access logic. If these pieces of code are intermingled in a single module/class you end up with a complex class which looks like Figure 1:
Figure 1 - A single module with multiple responsibilities
Because all the logic is intermingled it would be difficult to make changes without making the code more complicated and difficult to maintain. It would be difficult, for example, to do the following:
High cohesion is often a sign of a well-structured computer system and a good design, and when combined with loose coupling, supports the general goals of robustness, reliability, reusability, and understandability. Cohesion is increased if:
Advantages of high cohesion are:
While in principle a module can have perfect cohesion by only consisting of a single, atomic element - having a single function, for example - in practice complex tasks are not expressible by a single, simple element. Thus a single-element module has an element that either is too complicated, in order to accomplish a task, or is too narrow, and thus tightly coupled to other modules. Thus cohesion is balanced with both unit complexity and coupling.
Here is an example of high cohesion:
If the code which is responsible for user interface (UI) logic, business logic, and data access logic is split into separate modules then you end up with the structure which is an implementation of the 3-Tier Architecture as shown in Figure 2:
Figure 2 - separate modules with single responsibilities
")
With this structure it is easy to replace the component in one layer with another component without having to make any changes to any component in the other layers.
The wikipedia article on Dependency Injection contains the following statement:
Dependency injection aims to separate the concerns of constructing objects and using them, leading to loosely coupled programs.
This is not correct. Separation of concerns is not the objective of DI as that, in itself, is a pointless objective as it does not identify any benefits that this action produces. In actuality this separation is the means by which it achieves that objective, which is identified in The true purpose of Dependency Injection as follows:
The true purpose of DI is to provide a means to take advantage of polymorphism where multiple objects share the same method signature(s) but with different implementations. This allows another object to call one of those methods without knowing the identity of that dependent object and without knowing its implementation details. Instead of being tightly coupled to a single dependent object it is loosely coupled to a collection of interchangeable objects. The identity of the dependent object is chosen outside of the calling object and then injected into it, and that object then calls that method on whatever dependent object it has been given. In this way the calling object can be reused with a variety of different dependent objects.
Note that Dependency Injection is not the same as Dependency Inversion.
Dependency Injection (DI) is the solution to the principle of Inversion of Control (IoC). It manages the dependencies between objects by creating the dependent objects outside the object which uses that dependency. In other words, instead of objects configuring themselves they are configured by an external entity. But why should they be configured by an external entity? Consider the following statements made in Dependency Injection Considered Harmful:
Firstly, an object's interface should define the services that the object requires as well as those it provides.
Why should it? According to the principle of implementation hiding an object's interface should identify the service it provides but not how it provides it. If you violate this principle then, by association, you must also be violating the principle of encapsulation.
Secondly, the code that satisfies the requirements of an object by giving it a reference to the services of its collaborators is external to both the object and its collaborators.
Why should it? What exactly is wrong with an object knowing the identity of its collaborators (dependents)? In order to consume a service from a dependent object surely the consumer must know both the object and the method signature in order to consume the service offered by the dependent?
But how can this description be put into practice? Consider the following piece of code:
class Person {
function doStuff () {
....
$objAddress =& singleton::getInstance('Address');
$address = $objAddress->getPrimaryAddress($customer_id);
....
} // doStuff
} // end class Person
In this example the Person object is the consumer and the Address object is the dependency. This is a classic example of lazy loading, or Just In Time (JIT) processing, in which the initialization of the dependent object is deferred until the point at which it is actually needed. This can contribute to efficiency in the program's operation if properly and appropriately used. The opposite of lazy loading is eager loading, or Just In Case (JIC) processing, where the dependent object is initialised at a much earlier point in the program, but which may not actually be used at all. This would make the program less efficient as it would create a service that was never used.
Note that in the above example I am using the static method getInstance(<class_name>) on the singleton class instead of a separate <class_name>::getInstance() method within each and every class. This technique is described in The Singleton Design Pattern for PHP. Although it was initially designed to provide a single instance of a class some people have pointed out that it also performs a similar task to a service locator. You can call it what you like, but it does not alter the fact that it was designed to return a single instance of a class, and that is precisely what it does. Or, as William Shakespeare put it, "A rose by any other name would smell as sweet".
I do not use DI to inject the $objAddress object for one simple reason - the getPrimaryAddress method is not polymorphic. I do not have an alternative object which can satisfy the getPrimaryAddress() method as there is only one entity in the entire application which can supply addresses. If there are no alternative objects which can satisfy this method then providing the ability to switch to an alternative which does not and will not exist ever would be a pointless exercise.
This eager loading is a by-product of dependency injection in which the dependent object is initialised outside of its consumer and injected into it in one of several ways - constructor injection, setter injection or call-time injection.
However, when it comes to separating configuration from use there is an alternative method which uses lazy loading and which is known as a service locator.
This method means that the place where the Person object is instantiated needs to be changed:
from this:
require ('classes/person.class.inc');
$person = new Person();
to this:
require ('classes/person.class.inc');
require ('classes/address.class.inc');
$person = new Person(new Address);
The Person class itself would then need to be changed to this:
class Person {
var $objAddress;
function __construct($objAddress) {
$this->objAddress = $objAddress);
} // __contruct
function doStuff () {
....
$address = $this->objAddress->getPrimaryAddress($customer_id);
....
} // doStuff
} // end class Person
This method means that the place where the Person object is instantiated needs to be changed:
from this:
require ('classes/person.class.inc');
$person = new Person();
to this:
require ('classes/person.class.inc');
$person = new Person();
require ('classes/address.class.inc');
$person->setObjAddress(new Address);
The Person class itself would then need to be changed to this:
class Person {
var $objAddress;
function setObjAddress($objAddress) {
$this->objAddress = $objAddress);
} // setObjAddress
function doStuff () {
....
$address = $this->objAddress->getPrimaryAddress($customer_id);
....
} // doStuff
} // end class Person
This method means that the place where the method in Person object is called needs to be changed:
from this:
require ('classes/person.class.inc');
$person = new Person();
$result = $person->doStuff();
to this:
require ('classes/person.class.inc');
$person = new Person();
require ('classes/address.class.inc');
$person->doStuff(new Address);
The Person class itself would then need to be changed to this:
class Person {
function doStuff ($objAddress) {
....
$address = $objAddress->getPrimaryAddress($customer_id);
....
} // doStuff
} // end class Person
This to me seems wrong as you would be injecting an entity into and entity, which, according to How to write testable code and When to inject: the distinction between newables and injectables is not a good idea. Moreover, you would be violating the YAGNI principle by providing the ability to swap one address object for another when in reality there will only ever be a single object which can supply a postal address. This is why, in my framework, I never inject an entity into an entity, I only ever inject an entity into a service.
You should note here that the "Copy" program uses call-time injection as the identification of the input and output objects is performed in the same instruction which activates the program, as in $result = $copy($input, $output). As described in Object Types the device objects are examples of entity objects while the "Copy" program is an example of a service object.
Note that the above examples do not show the volume of code that would be required to deal with multiple dependencies, and in my application it is not unknown for an object to have 10 dependencies. Also, what about the situation where each of those dependent objects has dependents of its own?
You should also notice that implementing DI does not use fewer lines of code than when not using DI, which also means that it is not more efficient. The fact that the logic is now split over two components (or even more if you factor in a configuration file and a DI Container) also makes it longer to read and therefore more difficult to maintain.
This design pattern is described in wikipedia.
In his article Inversion of Control Containers and the Dependency Injection pattern Martin Fowler has this to say:
The choice between them (dependency injection or service locator) is less important than the principle of separating configuration from use.
In my framework each of the Model objects has only a single configuration which is taken care of in the class constructor when it calls the standard loadFieldSpec() method.
In Using a Service Locator he describes the mechanism thus:
The basic idea behind a service locator is to have an object that knows how to get hold of all of the services that an application might need.
This could be coded as follows in an object which wishes to use a service offered by the 'Foo' class:
$dependentObj = serviceLocator::getInstance('Foo');
The serviceLocator would then find the class which corresponds to the name 'Foo', then return an instance of that class using lazy loading. If it had access to a configuration file it would be possible to instruct it to substitute an instance of 'Foo' with something else.
Note that in my RADICORE framework I don't actually have a serviceLocator component, instead I use a singleton component. This results in code similar to the following:
$dependentObj = singleton::getInstance('Foo');
Note that in my framework I do not have a getInstance() method in any of my classes which forces every instance of that class to be a singleton, so I could easily switch to the following:
$dependentObj = new Foo;
If Dependency Injection is the solution, what is the problem that it is meant to solve? If you look carefully at the COPY program you will see that it is used to copy a file from one device to another and where the file can exist on any number of different devices. Instead of having the choice of devices and their particular implementations dealt with internally by some sort of switch statement, which would require that the program had prior knowledge of each possible device and its implementation, the choice of device is made externally and then injected into the program. This allows new device objects with their different implementations of the read() and write() methods to be created without having to amend the COPY program.
The problem can therefore be stated as:
Dependency Injection is the solution to the problem where an object has a dependency which can be supplied from a variety of interchangeable sources of the same type. Instead of identifying the actual source internally, which would require knowledge of all the possible alternatives, the choice is made externally, which means that new choices can be made available without having to modify the consuming object.
In order for me to accept that something is a good idea I need a concrete example that actually makes sense. The only sensible example I have found is the "Copy" program which can be found in the The Dependency Inversion Principle (PDF) written by Robert C. Martin in 1996.
It is also described in Dependency Inversion Principle, IoC Container, and Dependency Injection at codeproject.com. In this the Copy module is hard-coded to call the readKeyboard module and the writePrinter module. While the readKeyboard and writePrinter modules are both reusable in that they can be used by other modules which need to gain access to the keyboard and the printer, the Copy module is not reusable as it is tied to, or dependent upon, those other two modules. It would not be easy to change the Copy module to read from a different input device or write to a different output device. One method would be to code in a dependency to each new device as it became available, and have some sort of runtime switch which told the Copy module which devices to use, but this would eventually make it bloated and fragile.
The proposed solution is to make the high level Copy module independent of its two low level reader and writer modules. This is done using dependency inversion or dependency injection where the reader and writer modules are instantiated outside the Copy module and then injected into it just before it is told to perform the copy operation. In this way the Copy module does not know which devices it is dealing with with, nor does it care. Provided that each of the injected objects has the relevant read and write methods then it will work. This means that new devices can be created and used with the Copy module without requiring any code changes or even any recompilations of that module.
This Copy module shows the differences between having the module configure itself internally or externally:
read() and write() methods on whatever objects it has been given. New device objects can be created, or exiting objects amended, without having to amend the Copy module.Here is an example of how the refactored Copy module could be used:
$objCopy = new CopyProgram; $objInput = new deviceX(.....); $objOutput = new deviceY(.....); $result = $objCopy->copy($objInput, $objOutput);
Here it is clear that the external configuration option using Dependency Injection offers more flexibility as it allows the Copy module to be used with any number of devices without knowing the details of any of those devices.
Notice also that the copy() method in the copy object has arguments for the both the source (input) and target (output) objects which means that the objects are both injected and consumed in a single operation. There is no need to perform the inject() and consume() operations separately, so the idea that the Robert C Martin's article promotes such a thing is completely wrong. This is a prime example of where a relatively simple idea has been corrupted beyond recognition and made much more complicated. The idea that I must manage every one of my dependencies using some complicated Dependency Injection (DI) or Inversion of Control (IoC) mechanism does not fly in my universe as the costs outweigh the benefits.
You should also note the dependent objects are not injected and consumed in separate operations. The copy() method in the copy object does two things:
It is not good enough to say "Here is a design pattern, now use it" without identifying under what circumstances it is designed to provide some sort of benefit. If you don't have the problem which this design pattern is meant to solve then implementing the solution may be a complete waste of time. In fact, as well as being a total non-solution it may actually create a whole new series of problems, and that strikes me as being just plain stupid. But what do I know, I'm just a heretic!
In When to use Dependency Injection? by Jakob Jenkov I found the following:
Dependency injection is effective in these situations:
- You need to inject configuration data into one or more components.
- You need to inject the same dependency into multiple components.
- You need to inject different implementations of the same dependency.
- You need to inject the same implementation in different configurations.
- You need some of the services provided by the container.
These situations have one thing in common. They often signal that the components wired together represent different or independent concepts or responsibilities, or belong to different abstraction layers in the system.
In my framework the situations described in points #1, #2, #4 and #5 simply do not exist, which leaves only point #3. In this case where I have the same method appearing in multiple objects I can make use of polymorphism, which means that the object which contains that method can be one of several alternatives each of which has a different implementation behind that method. In this case the choice of which alternative to use is made outside of the calling object and the name of the dependent object is injected into it. This leads me to the following definition which I believe is easier to understand and more precise, therefore less easy to misunderstand and get wrong:
Dependency Injection is only a good idea when a consuming object has a dependency which can be switched at runtime between a number of alternatives, and where the choice of which alternative to use can be made outside of the consuming object and then injected into it.
In order to switch a dependency from one object to another it requires that the other object has a method with exactly the same signature. This sharing of method signatures is called polymorphism.
The Copy program cannot function without polymorphism. This is why Uncle Bob changed the ReadKeyboard() and WritePrinter() methods into the standard $object->Read() and $object->Write() methods on each of his different device objects. I have mirrored this behaviour in the RADICORE framework by having the same set of Create, Read, Update and Delete (CRUD) methods in each of my table objects.
So, the more polymorphism you have the more opportunities you have for dependency injection. In my framework each one of my 450 database tables has its own table class which inherits from the same abstract table class. My framework also has 40 reusable Page Controllers which communicate with their Model classes using methods defined in the abstract table class. This means that any of my 40 Controllers can communicate with any of my 450 Models. This produces 40 x 450 = 18,000 (yes, EIGHTEEN THOUSAND) opportunities for polymorphism, and where each of those 40 Controllers has 450 alternatives which can be injected.
You should also observe that the device objects are examples of entity objects while the "Copy" program is an example of a service object. These terms are explained below in Object Types.
As well as identifying when a particular design pattern may be a good idea it is also necessary to identify under what circumstances its use may be totally inappropriate, or its benefits either minimal or non-existent. In When to use Dependency Injection? by Jakob Jenkov I found the following:
Dependency injection is not effective if:
- You will never need a different implementation.
- You will never need a different configuration.
If you know you will never change the implementation or configuration of some dependency, there is no benefit in using dependency injection.
In my framework each of the Model objects has only a single configuration which is taken care of in the class constructor when it calls the standard loadFieldSpec() method.
In his article When does Dependency Injection become an anti-pattern? David Lundgren writes the following:
Just like any pattern it can become an anti-pattern when overused, and used incorrectly. If you are never going to be injecting a different dependency why are you using a dependency injector?
This wikipedia article contains the following caveat regarding DI:
However, there should exist a definite reason for moving a dependency away from the object that needs it. One drawback is that excessive or inappropriate use of dependency injection can make applications more complicated, harder to understand, and more difficult to modify. Code that uses dependency injection can seem magical to some developers, since instantiation and initialization of objects is handled completely separately from the code that uses it. This separation can also result in problems that are hard to diagnose. Additionally, some dependency injection frameworks maintain verbose configuration files, requiring that a developer understand the configuration as well as the code in order to change it. For example, suppose a Web container is initialized with an association between two dependencies and that a user who wants to use one of those dependencies is unaware of the association. The user would thus not be able to detect any linkage between those dependencies and hence might cause drastic problems by using one of those dependencies.
In his article How to write testable code the author explains the difference between entity objects (which are stateful) and service objects (which are without state). He goes on to say that entities can be injected into services but should never be injected into other entities.
So there you have it. If you build into your application a mechanism for changing dependencies, but you never actually use it, then all that effort is wasted. This is surely a clear violation of the YAGNI principle. On top of that, by inserting code which you never use you may make your application more difficult to maintain.
After searching through various articles on the interweb thingy I discovered that the benefits of DI are, in fact, extremely limited. In Jacob Proffitt's article I found the following:
The real reason that so many developers are using DI is to facilitate Unit Testing using mock objects.
A similar sentiment can be found in Jordan Zimmerman's article Dependency Injection Makes Code Unintelligible:
DI has gained support from the Test Driven Development community as it makes running tests easier.
So there you have it. DI does not provide any benefits outside of a testing framework as its only function is to provide the ability to switch easily between a real object and a mock object. But what is a mock object? This wikipedia article provides the following description:
In object-oriented programming, mock objects are simulated objects that mimic the behavior of real objects in controlled ways. A programmer typically creates a mock object to test the behavior of some other object, in much the same way that a car designer uses a crash test dummy to simulate the dynamic behavior of a human in vehicle impacts.
I first came across the idea of using mock objects many years ago when I read articles saying that before implementing a design using Object Oriented Programming (OOP) it must first be designed using the principles of Object Oriented Design (OOD) in which the software objects are designed and built before the physical database is constructed. This then requires the use of mock objects to access the non-existent database, and it is only after the software components have been finalised that you can then build the physical database and replace the mock objects with real objects. What Poppycock! As I am a heretic I do the complete opposite - I start with a database design which has been properly normalised, build a class for each database table, then build user transactions which perform operations on those table classes. I have made this process extremely easy by building a Data Dictionary application which will generate both the table classes and the user transactions for me. Notice that I have completely bypassed the need for any OOD.
I do not use mock objects when building my application, and I do not see the sense in using mock objects when testing. If I am going to deliver a real object to my customer then I want to test that real object and not a reasonable facsimile. This is because it would be so easy to put code in the mock object that passes a particular test, but when the same conditions are encountered in the real object in the customer's application the results are something else entirely. You should be testing the code that you will be delivering to your customers, not the code which exists only in the test suite.
If you really need to use mock objects in your testing then using DI to switch objects at runtime is not the only solution. An alternative to DI is the service locator pattern or possibly the service stub. In his article Inversion of Control Containers and the Dependency Injection pattern Martin Fowler has this to say:
A common reason people give for preferring dependency injection is that it makes testing easier. The point here is that to do testing, you need to easily replace real service implementations with stubs or mocks. However there is really no difference here between dependency injection and service locator: both are very amenable to stubbing. I suspect this observation comes from projects where people don't make the effort to ensure that their service locator can be easily substituted. This is where continual testing helps, if you can't easily stub services for testing, then this implies a serious problem with your design.
So if Martin Fowler says that it is possible to use a service locator instead of DI in unit testing, then who are you to argue otherwise?
It should be noted that I do not write automatic unit tests for reasons explained in Automated Unit Testing and TDD.
Before I describe how and where I use, or not use, DI in my application it would be helpful if I identified the application's structure.
Firstly let me state that I do not write public-facing web sites, or component libraries, I write business-facing enterprise applications where the data and the functions that can be performed on that data takes precedence over a sexy user interface. In the enterprise it is the data which is the most important asset as it records its business activities and helps identify where it is making its profits or losses. The software which manipulates that data comes a close second as it is easier to replace than the data itself.
I have been designing and building enterprise applications for several decades and have built reusable frameworks in each of my three main languages (COBOL, UNIFACE and PHP). It was while using UNIFACE that I became aware of the 3-Tier Architecture, so when I rebuilt my framework in PHP I deliberately chose to implement this architecture as its potential for developing reusable components was much greater than with my previous frameworks. After I had built my RADICORE framework a colleague pointed out that I had also implemented a version of the Model-View-Controller design pattern as shown in Figure 3:
Figure 3 - MVC plus 3 Tier Architecture
")
In his article How to write testable code the author identifies three distinct categories of object:
| Entities | An object whose job is to hold state and associated behavior. The state (data) can be persisted to and retrieved from a database. Examples of this might be Account, Product or User. In my framework each database table has its own Model class. |
| Services | An object which performs an operation. It encapsulates an activity but has no encapsulated state (that is, it is stateless). Examples of Services could include a parser, an authenticator, a validator or a transformer (such as transforming raw data into HTML, CSV or PDF). In my framework all Controllers, Views and DAOs are services. |
| Value objects | An immutable object whose responsibility is mainly holding state but may have some behavior. Examples of Value Objects might be Color, Temperature, Price and Size. PHP does not support value objects, so I do not use them. I have written more on the topic in Value objects are worthless. |
This distinction between Entities and Services is also discussed in When to inject: the distinction between newables and injectables.
Note also that business rules should be defined in entities, never in services. All services should be application-agnostic while entities should be application-centric.
If you think about the objects being used in Robert C Martin's Copy Program you should see that the devices are entities while the copy program is a service. Each of those entities (devices) must share the same methods so that any of them can be accessed from within the service (the "Copy" program) using the OO capability known as polymorphism. He is clearly showing a situation in which he is injecting entities into a service. One may draw from this the following conclusions:
My framework contains the following objects:
In my own framework I never inject an entity into an entity, I only ever inject an entity into a service:
Note that all domain knowledge is kept entirely with the Model classes for each domain/subsystem, which means that the Controllers, Views and DAOs are completely domain-agnostic. This means that they are not tied to any particular domain and can therefore be used with any domain.
A more detailed breakdown of the actual components is shown in Figure 4:
Figure 4 - My implementation of the MVC pattern
")
All the components in the above diagram are clickable links. Note that the "DML class" in the Model is actually the same as the Data Access Object in the 3-Tier Architecture.
With the RADICORE framework the following components are either part of the framework or are generated at runtime:
Note that in the above example the View component is only capable of generating HTML output, but my framework actually contains other components which can output the data in alternative formats such as PDF or CSV.
The following components are generated by the Data Dictionary in the framework when building an application:
This structure means that all application logic is confined to the Model classes in the Business layer, while the Controllers, Views and Data Access objects are completely application-agnostic and can be shared by any number of different applications.
When I build an application with RADICORE I always start with the database which I import into my Data Dictionary. I then export the details of each database table to produce a table class file and a table structure file. I can then amend the table class file to include any extra validation rules or business logic. If the table's structure changes all I have to do is regenerate the table structure file. When I build a user transaction, which does something to a database table, I go into the Data Dictionary, choose the table, the choose the Transaction Pattern, and when I press the button the relevant scripts are automatically created. The transaction is automatically added to the menu database so that it can be run immediately. Note that the elapsed time between creating a database table and running the transactions which maintain that table is under 5 minutes, and all without writing a single line of code - no PHP, no SQL, no HTML.
With the RADICORE framework an end-user application is made up of a number of subsystems or modules where each subsystem deals with its own database table. The framework itself contains the following subsystems:
These RADICORE subsystems deal with 46 database tables, 104 relationships and 305 transactions.
My main ERP application contains additional subsystems which were based on the database designs found in Len Silverston's Data Model Resource Book:
These ERP subsystems deal with 268 database tables, 458 relationships and 2,138 user transactions.
This gives a combined total of 314 database tables, 562 relationships and 2,443 transactions.
If you look at the reusable components in the RADICORE framework you should see the following statistics:
Having explained what DI means and how it can be implemented, I can now explain where I use DI in my framework.
Each of my 2,443 user transactions has its own component script which looks something like the following:
-- a COMPONENT script (mnu_user(add1).php) <?php $table_id = "mnu_user"; // identifies the model $screen = 'mnu_user.detail.screen.inc'; // identifies the view require 'std.add1.inc'; // activates the controller ?>
Note that this example uses the 'add1' controller, although there are over 40 different controllers, one for each of my Transaction Patterns. This script "injects" the name of the target class file into the designated Controller using the variable $table_id.
-- a CONTROLLER script (std.add1.inc) <?php require "classes/$table_id.class.inc"; $object = new $table_id; $fieldarray = $object->insertRecord($_POST); if (empty($object->errors)) { $result = $object->commit(); } else { $result = $object->rollback(); } // if ?>
Using DI here has great benefits as the number of Model classes is quite huge (300+), and new classes for new database tables can be generated at any time. The method names used within each Controller are common to every Model class (due to the fact that they are all inherited from the same abstract table class) which is why they can operate on any Model class.
Note also that the $screen variable does not actually identify the View object which generates HTML as there is only one, and that is hard-coded into the controller. What it does do is provide screen structure information which is used by the View object to identify the following:
The View object which generates PDF output has its own controllers and uses a report structure file.
Those of you who are still awake at this point may notice some things in the above code which are likely to make the "paradigm police" go purple with rage.

 There may be other rules that I have violated, but I really don't care. As far as I am concerned those are nothing but implementation details, and provided that what I have achieved is in the spirit of DI then the implementation details should be irrelevant and inconsequential. The spirit of DI is that the consumer does not contain any hard-coded names of its dependents so that it can be passed those names at run-time. There is no effective difference between being passed a pre-instantiated object and being passed the name of a class which can be instantiated into an object. I have still achieved the objective that the consumer (in this case the Controller) can be made to operate with whatever dependent (in this case the Model) is passed to it, so my Controller can be made to operate with any Model in the application. I have achieved the desired result, and that is all that matters. The fact that I have achieved this in a different way just shows that I am capable of "thinking outside the box", of "stretching the envelope" whereas the "paradigm police" are constrained by their own narrow-mindedness and short-sightedness. I am a pragmatist, not a dogmatist, which means that I am results-oriented and not rules-oriented. If I can achieve the desired results by breaking a particular set of rules, then it does not say much about the quality of those rules, does it?
There may be other rules that I have violated, but I really don't care. As far as I am concerned those are nothing but implementation details, and provided that what I have achieved is in the spirit of DI then the implementation details should be irrelevant and inconsequential. The spirit of DI is that the consumer does not contain any hard-coded names of its dependents so that it can be passed those names at run-time. There is no effective difference between being passed a pre-instantiated object and being passed the name of a class which can be instantiated into an object. I have still achieved the objective that the consumer (in this case the Controller) can be made to operate with whatever dependent (in this case the Model) is passed to it, so my Controller can be made to operate with any Model in the application. I have achieved the desired result, and that is all that matters. The fact that I have achieved this in a different way just shows that I am capable of "thinking outside the box", of "stretching the envelope" whereas the "paradigm police" are constrained by their own narrow-mindedness and short-sightedness. I am a pragmatist, not a dogmatist, which means that I am results-oriented and not rules-oriented. If I can achieve the desired results by breaking a particular set of rules, then it does not say much about the quality of those rules, does it?
If you look at an example of one of my page controllers you will see the following code at the end of the script:
// build list of objects for output to XML data $xml_objects[]['root'] = &$dbobject; // build XML document and perform XSL transformation $view = new radicore_view($screen_structure); $html = $view->buildXML($xml_objects, $errors, $messages); echo $html;
Here is an example where the Controller deals with two tables in a one-to-many/parent-child/outer-inner relationship:
// build list of objects for output to XML data $xml_objects[]['root'] = &$dbouter; $xml_objects[][$dbouter->getClassName()] = &$dbinner; // build XML document and perform XSL transformation $view = new radicore_view($screen_structure); $html = $view->buildXML($xml_objects, $errors, $messages); echo $html; exit;
Using DI here has great benefits as the number of Model classes is quite huge (300+), and new classes can be generated at any time. All the application data within each object is held within a single array called $fieldarray, and this data can be extracted and converted into XML using standard code which does not require the prior knowledge of any table or column names.
This is an example of call-time injection as the array of possible model objects is passed as an argument in the buildXML() method. An array is used as there may be a number of different model objects, and this way is more flexible than having each object as a separate argument.
I have been told on more than one occasion that I am not allowed to pick and choose if I want to implement DI or not. It is "best practice" to use DI at every conceivable opportunity whether it has measurable benefits or not, so if I don't then I am not following best practice, I am not toeing the party line. This makes me a heretic, an unbeliever and an outcast, and my code must be crap.
Pardon me if I take all these criticisms with a pinch of salt. I prefer to think before I implement a particular pattern or technique, and if I think that my code won't benefit from its use then I simply won't use it. I do not let other people do my thinking for me, and I do not think that the blanket (aka "without thinking") use of DI is a good idea. It would appear that I am not the only one who thinks this way. In Dependency Injection Objection Jacob Proffitt states the following:
The claim made by these individuals is that The Pattern (it can be any pattern, but this is increasingly frequent when referring to Dependency Injection) is universally applicable and should be used in all cases, preferably by default. I'm sorry, but this line of argument only shows the inexperience or narrow focus of those making the claim.
Claims of universal applicability for any pattern or development principle are always wrong.
In his article Non-DI code == spaghetti code? the author makes the following observation:
Is it possible to write good code without DI? Of course. People have been doing that for a long time and will continue to do so. Might it be worth making a design decision to accept the increased complexity of not using DI in order to maximize a different design consideration? Absolutely. Design is all about tradeoffs.
It is of course possible to write spaghetti code with DI too. My impression is that improperly-applied DI leads to worse spaghetti code than non-DI code. It's essential to understand guidelines for injection in order to avoid creating additional dependencies. Misapplied DI seems to involve more problems than not using DI at all.
In his article How to write testable code the author identifies three distinct categories of object: value objects, entities and services. He states that it is only service objects which should be considered as "injectable" while value objects and entities should be considered as "newable" or "non-injectable". This then provides the following rules:
a newable can only ask for other newables or primitives in its constructor, while an injectable should only ask for other injectables in its constructor.
I disagree with this rule as I only allow entities (newables) to be injected into services (injectables). In my framework I allow entities to be injected into services but I do not allow entities to be injected into entities. I also do not allow services to be injected into entities, so I am in agreement with the following statements:
A corollary to this rule is of course that newables should not be injected with injectables. Why not? Because it will lead to pain for the client of the newable. And tests of course are clients, so it will lead to testing pain also. Why? Because injecting an injectable creates a dependency for the newable. And if the newable has a dependency, then it can no longer be tested in isolation easily. Every time a client wants to create this newable, it's going to have to create this dependency also. So every test that uses an instance of this newable is going to have to either create a mock for the injectable or use the real injectable collaborator. In other words, the setup for any test involving this newable is now more complex. The complexity can spiral out of control quickly since dependencies are transitive. Instead of just being able to easily "new" these collaborators, the tests now have extra complexity because the rule to not inject into newables was ignored.
In a recent Sitepoint discussion which was supposed to evaluate the arguments for NOT using DI, and which used this very article as a starting point, it was quite obvious that the vast majority of people who joined this discussion weren't interested in listening to my arguments, they could do nothing but insist that DI was a very good idea and that I was a very bad boy for daring to suggest otherwise. Below are the places in my framework where I have been told repeatedly that I should use DI, but where I absolutely refuse to do so. Perhaps when you consider my arguments in the context of my framework you may consider that I actually have a valid point after all.
When I have worked on other people's applications using other frameworks I have always seen the database object being instantiated by the controller and injected into the model. When I explain that I do it differently the response is always the same: "This is way it's supposed to be done, so if you don't do it this way then you must be wrong". These people may have heard of the MVC design pattern but they have rarely heard of its earlier counterpart the 3 Tier Architecture to which I was exposed years before I dabbled with OO and design patterns. It is one of the rules of this architecture that the Presentation layer can only communicate with the Business layer, which means that it absolutely must not communicate with the Data Access layer. Each layer in this architecture is only allowed to know of the layer immediately below it, so it is only the Business layer which is allowed to communicate with the Data Access layer.
Another point to consider is that a Model class may not actually touch the database, in which case the effort of instantiating and injecting a database object is totally wasted. For example, a Controller calls the insertRecord($POST) method on a Model object, but this method has to perform various steps as shown in the UML diagram shown in Figure 5:
Figure 5 - UML diagram for Add 1
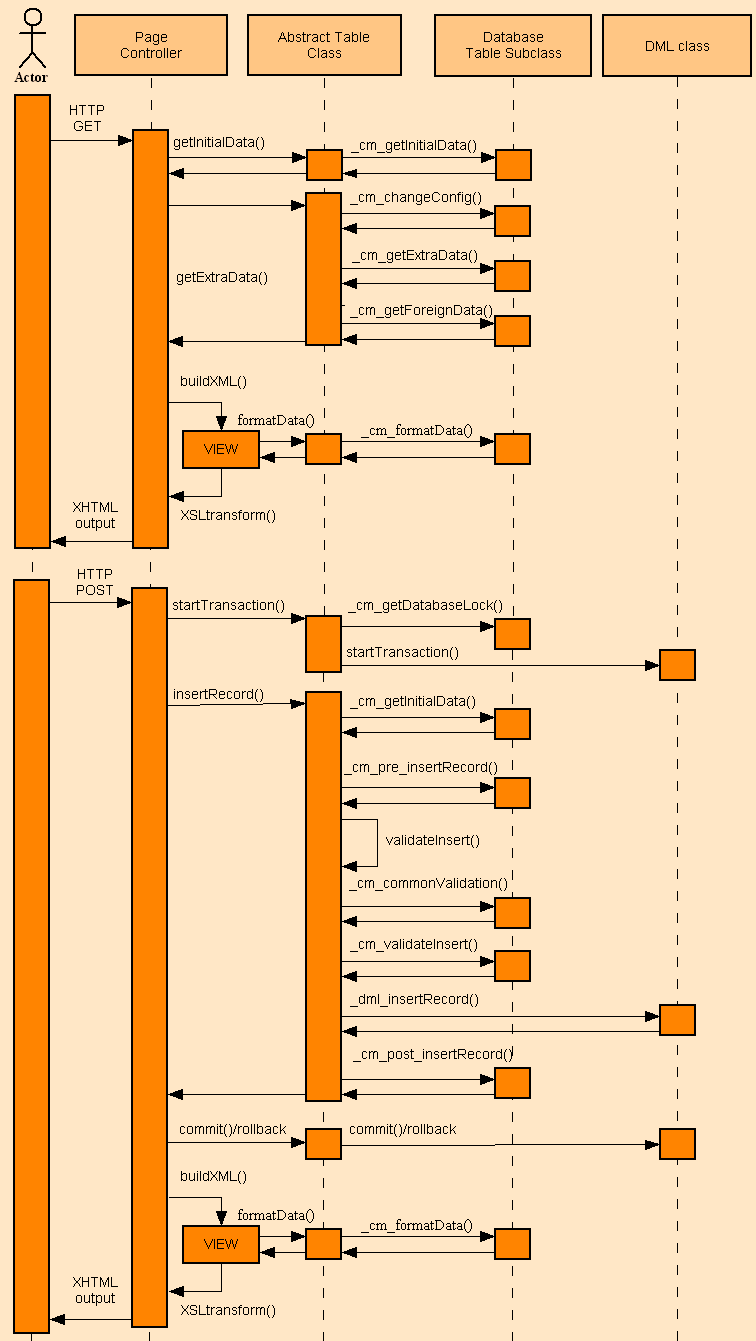
If the validation fails then the Model returns to the Controller without touching the database. If the validation succeeds then the _dml_insertRecord() method will obtain an instance of the Data Access Object (DAO) for the appropriate server then use that instance to construct and execute the relevant SQL query. This is an example of lazy loading where an object is not initialised until it is actually needed.
While most installations will have all its databases in a single database server, some may have them split across different servers with different IP addresses, or perhaps using a different DBMS engine for each server. This is not a problem as the framework will use a separate instance for each database server. It is not restricted to a single database instance for the entire application.
In a complex application it is more than likely that a Model class may need the services of other objects in addition to the DAO. This may include my date and validation objects, but it may also include any number of the other database table objects. Consider the following code:
class Person {
function _cm_getForeignData ($fieldarray) {
....
$objAddress =& singleton::getInstance('Address');
$address = $objAddress->getPrimaryAddress($customer_id);
$fieldarray = array_merge($fieldarray, $address);
....
} // _cm_getForeignData
function _cm_post_insertRecord ($fieldarray) {
....
$objAddress =& singleton::getInstance('Address');
fieldarray = $objAddress->insertRecord(fieldarray);
if (!empty($objAddress->errors)) {
$this->errors = array_merge($this->errors, $objAddress->errors)
} // if
....
} // _cm_post_insertRecord
} // end class Person
In this example the 'Person' object needs to call upon the services of the 'Address' object in order to carry out its processing. It is calling different methods in different stages of the processing cycle - one when reading and another when inserting.
I have been told that this produces tight coupling between the 'Person' and 'Address' objects, but if you look closely you will see that my use of a simple and stable interface means that it actually matches the description of loose coupling. While it is correct to say that every dependency, whether hard-coded or injected, will automatically produce coupling, it is totally incorrect to say that it automatically produces tight coupling. The strength of that coupling is determined by totally separate factors.
The method $objAddress->getPrimaryAddress($customer_id) presents a simple and stable interface, and I can change its internal implementation without having any effect on the calling object. Note that this method can be called from any object which contains a value for $customer_id, and is not limited to just the 'Person' object.
The method $objAddress->insertRecord(fieldarray) also presents an interface which couldn't possibly be simpler. Notice that I do not have to filter the contents of $fieldarray before I pass the data to the object. I am totally unconcerned about the current contents of $fieldarray, and I am totally unconcerned about the structure of the 'Address' table. The standard processing within each table object will automatically ignore any field which does belong in that table, validate what is left over, and populate the $errors array if anything goes wrong. This means that I could change the structure of either the 'Person' or 'Address' tables without having to change this code. What could possibly be simpler?
I have been told that this method makes it impossible to switch the dependency, in this case the 'Address' object, to another object. If you studied my application structure you should notice that each Model class is associated with a single database table, and as my application contains a 'Person' table as well as an 'Address' table I need a separate class for each. It should also be obvious that if a user transaction displays information from the 'Person' table, but also needs to display the person's primary address, then it must communicate with the separate 'Address' object in order to obtain that data. The idea that I should use DI to provide me with the ability to switch this dependency to another Model class is therefore totally ludicrous as I can only obtain address information from the 'Address' object. Switching to any other object, such as 'Product', 'Invoice' or 'Inventory', would not produce any usable results. So why should I pollute my application with code that provides me with the ability to do something that I am never going to do? This sounds like a serious violation of the YAGNI principle.
However, should it be necessary for me to include the ability to switch dependencies in my application I would not necessarily have to do it using DI - I could modify my singleton class, which is similar to a service locator, to use a configuration file to switch class names at runtime.
The example above which uses $objAddress->getPrimaryAddress($customer_id) is almost identical to the one described in Design pattern - Inversion of Control and Dependency Injection which has a set of theoretical problems:
Consider the example where we have a customer class which contains a 'clsAddress' class object. The biggest issue with the code is tight coupling between classes. In other words the customer class depends on the address object. So for any reason address class changes it will lead to change and compiling of 'clsCustomer' class also. So let's put down problems with this approach:
- The biggest problem is that customer class controls the creation of address object.
- Address class is directly referenced in the customer class which leads to tight coupling between address and customer objects.
- Customer class is aware of the address class type. So if we add new address types like home address, office address it will lead to changes in the customer class also as customer class is exposed to the actual address implementation.
Of all the statements in that quote I can only find one with which I agree: the customer class depends on the address object
. All the others are questionable.
Another so-called "problem" which theoretically arises because of my refusal to use DI has been expressed as follows:
As you can see from the above list all those "problems" do not actually exist in my application, so if the problems do not exist then can you please explain to me in words on one syllable what benefits I would obtain by implementing DI as the solution?
Ralph Schindler's article contains the following code snippet as a "solution":
A sample Dependency Injection Container (DIC) // construction injection $dependency = new MyRequiredDependency; $consumer = new ThingThatRequiresMyDependency($dependency);
This looks extremely simple, but the simple fact is that it is too simple. Rather than providing a workable solution it simply hints at what part of one might look like, so it does not go far enough. As far as I am concerned it produces more questions than answers.
Questions, questions, and yet more questions. This article has *NOT* convinced me that dependency injection is a good thing at all, nor has it provided me with sample code that I can try out myself to see if any of the claims can be substantiated. I therefore consider the article to be a waste of space and unworthy of serious consideration, especially from an OO heretic such as me.
It should also be pointed out that DI does not remove any dependencies, it merely separates the dependent's creation from its consumption. The consuming object is still dependent on the dependent object, it just doesn't control when and how it is created. Also, the number of changes you can make in the DI container without having to make corresponding changes in the consuming object are rather limited.
After studying the principles of OOP, and having implemented those principles in several enterprise applications, I have come to the conclusion that when using DI to inject objects which never actually get to be changed, as explained in when DI is a bad idea, then DI has a serious defect in that it violates the principle of encapsulation which states
an object contains both data and methods which act upon that data, but that the implementation of those methods is hidden
This is known as implementation hiding (which is not the same as information hiding). In other words a method's signature, the API, identifies what can be done but gives absolutely no indication as to how it will be done. This allows for a method's implementation to be changed at any time without affecting any external entity which uses that method. The external entity should not even be aware that the method requires the use of other objects to carry out its function, and therefore should not have to inject those dependencies into the object before the method can be used. If an object's dependencies do not have any effect on the result, such as it will always return an address regardless of which which address object it is given (and there is only one such object, after all), then the use of DI is totally unnecessary. If you call the $objPerson->getData($person_id) method to get a person's data then all you should need to supply is the person's identity and not care what the method has to do or where it has to look in order to obtain that data. You should not need to supply a list of dependencies which have the effect of saying "use this object for this data, and that object for that data".
In his article On Dependency Injection and Violating Encapsulation Concerns Bryan Cook has this to say:
If you are allowing callers to construct the class directly, then you are most certainly breaking encapsulation as the callers must possess the knowledge of how to construct your class. However, regardless of the constructor arguments, if callers know how to construct your class you are also coupling to a direct implementation and will undoubtedly create a test impediment elsewhere.
I would like to comment on the phrase you are most certainly breaking encapsulation as the callers must possess the knowledge of how to construct your class
. This assumes that the class requires some sort of configuration before it can be used, but what if no configuration is actually required at all? In my framework all I have to do to turn a class, ANY class, into an object is as follows:
$dbobject = new $class_name; -- OR -- $dbobject = singleton::getInstance($class_name);
Note here that I can still use both methods in my code, so I only create a singleton if I actually want a singleton.
Each of the objects which exist in my Business layer, which incidentally are Models in my implementation of the MVC design pattern, represents a single database table. Each of these classes (and I have over 300 of them) inherits a vast amount of common code from an abstract table class, and all I need to turn an abstract class into a concrete class is contained in the class constructor.
Can you explain to me, in words of one syllable, how this can possibly create a test impediment?
Disco with Design Patterns: A Fresh Look at Dependency Injection
I recently came across an article called Disco with Design Patterns: A Fresh Look at Dependency Injection which contains some statements which I think are indicative of faulty thinking. The opening paragraph states the following:
Dependency Injection is all about code reusability. It's a design pattern aiming to make high-level code reusable, by separating the object creation / configuration from usage.
I disagree with this statement for the following reasons:
$dbobject = new $class_name; $result = $dbobject->method();
The idea that I should put those two lines of code in different places strikes me as having no advantages whatsoever, so excuse me if I choose to ignore it.
He goes on to show a code sample with the following explanation:
As you can see, instead of creating the PDO object inside the class, we create it outside of the class and pass it in as a dependency via the constructor method. This way, we can use the driver of our choice, instead of having to to use the driver defined inside the class.
This again points to a fault in the way that his code was designed. I can achieve what he seeks to achieve without the overhead of DI simply because of a different design.
_getDBMSengine($dbname) method which exists in the abstract table class which is inherited by all concrete table classes. This method uses information in the configuration file to determine which database driver to use (a choice between MySQL, PostgresSQL, Oracle and SQL Server) for that particular database name, then returns an instance of that driver's object. Note that this instance is a singleton and can be used to access any table within the same database.This design means that no Model/Business object is tied to a particular database driver, which means that I can switch my entire application from one DBMS to another simply by changing a setting in the configuration file. It is even possible, within a single user transaction, to access different databases through different drivers. This means that none of my table classes is tightly coupled to a particular DBMS, and this has been achieved WITHOUT the use of DI. So to say that I can only achieve this by using DI is absolute nonsense.
Although the article says that Dependency Injection is all about code reusability
it does not explain precisely how it aids in that reusability. One description is that it separates a dependent object's instantiation from its use
, but that is complete rubbish. As explained above in the introduction the true purpose of dependency injection is to provide a mechanism to take advantage of polymorphism so that you can swap the identity of a dependent object at runtime.
The article then goes on to say the following:
There's one drawback to this pattern, though: when the number of dependencies grows, many objects need to be created/configured before being passed into the dependent objects. We can end up with a pile of boilerplate code, and a long queue of parameters in our constructor methods. Enter Dependency Injection containers!
None of my Model objects needs to be configured as they only have a single configuration which is taken care of by standard code in the constructor. I never instantiate any dependent objects in the constructor, so I do not end up with piles of boilerplate code. This means that I can instantiate any object with nothing more than a single line of code. If I don't have piles of boilerplate code then I have no need for a dependency injection container. If a Model has a dependency on another Model then I instantiate that object and call one of its methods with code similar to the following:
$dbobject = new $class_name; -- OR -- $dbobject = singleton::getInstance($class_name); -- followed by --- $result = $dbobject->method(...);
By saying that the above method is wrong and that I MUST use DI to separate the object instantiation from the object's method call the author of that article is telling me to write code that serves no useful purpose, and as far as I am concerned that is a violation of the KISS principle. I write simple code that works, and I only add complexity when it doesn't work. I will not use the added complexity of DI if its sole purpose is to provide a facility that I will never use. Only a dogmatist would suggest such a thing, and I am not a dogmatist, I am a pragmatist.
If I used DI everywhere instead of only when it provided genuine benefits then I would be adding unnecessary complexity. If the resulting code became so long or complex that it required another solution in the form of a DI container then I would be adding another layer of complexity on top of unnecessary complexity. If the cure for a perceived problem is so complex that it has side effects which in turn require even more solutions, then all this added complexity will do nothing for the code except to make it slower to run and more difficult to understand and therefore maintain. Has he never heard of the saying Prevention is better than Cure? Instead of trying to solve the problem of bad design with more bad code the pragmatist's method is to come up with a better design that avoids the problem altogether. Once the problem disappears there is no need for a "solution" which simply hides the symptoms in another piece of code. If I do not have the need to swap implementations then I do not have the need for any code which enables me to swap implementations. If I do not use DI then I do not experience any of the problems which using DI creates, and if I don't experience any of those problems then I do not have to pollute my code with useless solutions.
I prefer to solve my software problems by designing solutions which address the problem directly instead of going through multiple layers of indirection. This philosophy is echoed in the following statement which is usually attributed either to David Wheeler or Butler Lampson:
There is no problem in computer science that cannot be solved by adding another layer of indirection, except having too many layers of indirection.
I am constantly amazed at the way in which some people, in an attempt to prove that they are experts on the matter, criticise my work with arguments which distort what I have actually written. Take the following as examples:
The following statement was made in this post:
The alternative to DI is another method of dependency resolution In your case singletons which are widely acknowledged to be a bad idea.
You clearly do not understand the point which I am trying to make, which is that the alternative to using DI is *NOT* to use DI. When using DI you instantiate a dependent object in one place then consume its services in another place. When *NOT* using DI you instantiate the object and consume its services in the *SAME* place, as in the following code sample:
$dbobject = new $class_name; -- OR -- $dbobject = singleton::getInstance($class_name); -- followed by -- $result = $dbobject->doStuff(...);
Notice here that I can use whatever mechanism I like to obtain the object instance, I am not saying that it *MUST* be via a singleton. I would also like to point out that the claim that "singletons are bad" is entirely dependent on how they are implemented. A common approach is to have a getInstance() method inside each class and force every instantiation to follow this path. A less common approach is to use a single getInstance method which exists in a separate singleton class. In this way I still have the choice on how I instantiate the chosen object.
The following statement was made in this post:
tony_marston404:Actually I'm saying 'Show me a situation where another approach is preferable to DI' and you have repeatedly failed to do so.
I am not asking for advice on how to use DI, I am asking the question "under what circumstances is DI an inappropriate solution?" All you can do is say "there are NO circumstances where DI is inappropriate". That does not leave any scope for further discussion.
I suggest you read When is Dependency Injection a bad idea? where I have provided quotes from several different sources which identity when using DI does not provide any benefits. If a "solution" does not provide any benefits then what is the point of implementing that solution?
The following statement was made in this post:
tony_marston404:This is a flat out lie.
and in the process it introduces more complexity, more levels of indirection, more code to execute, more code to read and understand, and the potential for more bugs.
This:class Foo { } class Bar { public $foo; public function __construct(Foo $foo) { $this->foo = $foo; } } new Bar(new Foo);is fewer lines of code, less complex and fewer method calls executed than ...
I disagree. The code which I *ACTUALLY* use (near enough) is as follows:
class Foo {
}
class Bar {
function dostuff() {
....
$dependency = singleton::getInstance('foo');
$result = $dependency->doOtherStuff();
....
}
}
$table_id = 'bar'; <== code contained within a component script
...
$dbobject = new $table_id; <== code contained within a page controller
Notice here that the page controller does not have the identity of its Model class hard-coded anywhere within it. This is because each page controller is a pre-written and reusable object supplied within the framework whereas each user transaction has its own unique component script which is generated specifically for that user transaction. It is not possible for the page controller to inject any dependencies into the Model as the number of dependencies may vary between one Model and another. Some Models have no dependencies whereas other Models may have several.
For reasons already stated I *NEVER* inject a Model into another Model as the dependent Model always has a single source which will *NEVER* change. For example, I have a Customer table and a Postal Address table, each of which has their own dedicated class. If within the processing of the Customer object I wish to obtain that customer's postal address then there is only one source for that address data, so providing the ability to switch to an alternative source when there will *NEVER* be an alternative would be, in my humble opinion, a complete waste of time. It would also be a violation of YAGNI. That is why I don't do it, and no amount of complaining from my "elders and betters" will ever convince me otherwise.
The following statement was made in this post:
You cannot understand the benefits of DI yet you're coming here arguing that it doesn't have any benefits. They are two different issues. Your lack of understanding is not an argument in itself and writing articles and arguing that "DI is evil" yet providing no sources and code examples that uses known bad practices is detrimental to others.
It is quite obvious to me that you are criticising what I wrote without actually reading what I wrote. DI has benefits in some circumstances but not in others. I have also identified those places in my framework where I do use DI as well as those places where I do not. As for references, if you bothered to visit my references section you would see dozens of articles written by other people who, like me, argue against the idea that DI is the best idea since sliced bread.
Although this article contains bucketloads of words to describe dependency injection I have eventually realised that there are too many levels of indirection and too much beating about the bush. I prefer explanations which are simple, concise and to the point. It wasn't until after I realised that I had accidentally created an implementation which achieved the objectives if DI that I decided to formulate my own simplified description which any novice programmer would find easier to understand.
- Dependency Injection is only useful when an object has a dependency which can be varied at runtime as it allows a different dependent object to be used. If there is only one object which can be used as a dependency then the ability to switch to another object is pointless.
- You cannot have Dependency Injection without polymorphic methods. You can have polymorphism without DI, but that would be wasting a golden opportunity.
- Polymorphism requires that different objects share the same method signature(s). This is done usually through inheritance, but need not be. All that is required is that the same method signature appears in several different classes, and that can be done by hard-coding.
- To implement DI you write code which calls one or more known polymorphic methods on an unknown object where the identity of that object is not supplied until runtime. How you supply that identity is up to you. You may either supply a complete object or the name of a class which can be instantiated into an object.
- The example in Robert C Martin's article shows how entity objects (the devices) are injected into a service object (the Copy program). While this is logical it would seem to be illogical to inject a service into an entity, to inject a service into a service, or to inject an entity into an entity.
Is that simple enough? Is it still accurate?
While DI has benefits in some circumstances, such as shown in the Copy program which injects two entity objects into a service object, I do not believe in the idea that it automatically provides benefits in all circumstances, such as injecting an entity object into another entity object. This is why I consider that the application of DI in the wrong circumstances should be considered as being evil and not a universal panacea or silver bullet. In fact, in the wrong circumstances it could even be said that Dependency Injection breaks encapsulation. Although I have found some places in my framework where I have made use of DI because of the obvious benefits it provides, there are some places where I could use DI but have chosen not to do so.
In this article I hope that I have exposed the following ideas as being questionable if not downright false:
So there you have it. Dependency Injection is not a foregone conclusion, it needs to be justified. Unfortunately most OO programmers do not have the brain power to evaluate DI to see if it would actually provide any benefit in their particular circumstances. Either they are told by a supposed "superior" that they should always implement it, in which case they obey without question just like a bunch of trained monkeys, or they hear about a new 'cool' design pattern and they rush to implement it just to prove to their peers that they are pattern experts.
Ralph Schindler's article Learning About Dependency Injection and PHP, and his follow-up article called DI, DiC, & Service Locator Redux, is full of smoke and mirrors and no substance, and without proper substance I cannot take DI seriously. As far as I am concerned it is just a big joke, a big con, just like most of the other design patterns. This is another one to be added to my "to be ignored" list.
In his article When does Dependency Injection become an anti-pattern? David Lundgren writes that, although he starting using it because it was the 'hip' thing to do, he eventually realised that by overuse or incorrect use it actually became an anti-pattern. He uses these words:
My belief that dependency injection was going to be the cure all for my work project seems to have backfired. We don't ever change dependencies dynamically, and have only changed dependencies once in the three years of the project. I never use the DI container for testing and my code seems to be a more complex as now I have to manage the dependencies in multiple places.
As far as I am concerned using this pattern in inappropriate circumstances does not solve a problem, it merely moves some code to a different part of the application and thus creates a different class of problem. The dependent object still needs to be instantiated, so if you move this action to a DI container you are creating the "problem" of having to manage and configure this container. Is it really worth the effort?
Here endeth the lesson. Don't applaud, just throw money.
It appears that I am not the only one who is not impressed with the idea of Dependency Injection. Here are a few articles I found on the interweb thingy:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are some newsgroup posts which criticise my point of view:
| 13 Mar 2023 | Added A simplified definition. |
| 17 Feb 2022 | Added Criticisms by so-called "experts". |
| 01 Oct 2016 | Amended The "copy" program to show that the dependent objects are not injected and consumed in separate operations. |
| 01 Jul 2016 | Added Comments on Disco with Design Patterns: A Fresh Look at Dependency Injection. |
| 21 Feb 2015 | Added When is Dependency Injection a good idea?
Added When is Dependency Injection a bad idea? Added My application structure Added Where I do use Dependency Injection Added Where I don't use Dependency Injection Added Dependency Injection breaks encapsulation. |
| 08 Jun 2011 | Added My heretical implementation of DI. |