")
I did not pull the design of my RADICORE framework out of thin air when I started programming in PHP, it was just another iteration of something which I first designed and developed in COBOL in the 1980s and then redeveloped in UNIFACE in the 1990s. I switched to PHP in 2002 when I realised that the future lay in web applications and that UNIFACE was not man enough for the job. PHP was the first language I used which had Object-Oriented capabilities, but despite the lack of formal training in the "rules" of OOP I managed to teach myself enough to create a framework which increased my levels of productivity to such an extent that I judged my efforts to be a great success. In the following sections I trace my path from being a junior programmer to the author of a framework that has been used to develop a web-based ERP application that is now used by multi-national corporations on several continents.
In 1971 when I was interviewed for my first job in IT (or Data Processing as it was known in those days) my interviewer was not interested in any academic qualifications. He gave me an aptitude test to see if I had a logical mind as he considered that to be more important than anything else. Although I started off as a computer operator I taught myself COBOL in order to modify a program that was used in the operations department. This was tricky as it was unstructured, undocumented and badly written, but somehow I succeeded. This impressed my boss so much he arranged for me to move into a programming department where my first task was to fix bugs in a log file analysis program. This was much larger and more complicated, but easier to follow as it had a proper structure. Once I found out what the program did I discovered that some of the bugs were in the design as the original author did not understand how the logs were written so the structure of his design was out of step with the structure of the problem. That is when I learned the importance of being able to combine logic and structure - you need to work out the logic and structure of the problem you are trying to solve before you can work out the logic and structure of the solution you are trying to write. A later course in Jackson Structured Programming reinforced the view that you needed to analyze the structure of the input data before you could produce a program design based on those data structures, so that the program control structure handled those data structures in a natural and intuitive way.
My pre-PHP history is explained in more detail in My Career History
It is important to note that programming on a UNIVAC mainframe did not involve screens and keyboards, it was coding pads and punched cards. We wrote our code on sheets of paper from a coding pad, sent those sheets to the punch room where the operators used keypunches to turn them into punched cards which were then returned to us. After checking these cards we would fill out a job sheet which we would attach to those cards, then submit the cards and job sheet to the computer room so that the operators could load in the deck of cards and schedule its run time. The results were printed on fan-fold paper which we collected from the computer room after the job was run. Everything in those days was run as batch jobs, there was no online processing. We usually worked on our code during the day, which involved a lot of desk checking, submitted our jobs for processing overnight, then collected the printed output the next morning.
As there was no online processing there was also no online debugging. If our program aborted it would print a dump of the program's memory which had one part for the data and another part for the code, and we had to work out from the memory addresses in use at the time of the crash what went wrong. This was a long and tedious task. As a debugging aid all we could do was print out certain values while the program was running to give an indication of where it was in the code and what it was doing.
COBOL is a language where an executable program is constructed in several stages. The source code, which is maintained in a text file, has to be compiled into intermediate files known as Relocatable Binary. There is one of these intermediate files for each file of source code, thus allowing a large program to be constructed from smaller pieces. A final link process would then assemble these intermediate files into an executable program file. One of the intermediate files would have to be identified as the starting (or MAIN) procedure while all the others would be treated as subprograms.
When I joined my first development team as a junior COBOL programmer we did not use any framework or code libraries, so every program was written completely from scratch. As I wrote more and more programs I noticed that there was more and more code that was being duplicated. There was no central library of reusable code in any of these projects, so the only way I found to deal with this when writing a new program was to copy the source code of an existing program which was similar, then change all those parts which were different. It was not until I became a senior programmer in a software house that I had the opportunity to start putting this duplicated code into a central library so that I could define it just once and then call it as many times as I liked, thus increasing my productivity. When I became team leader I made my personal library available to the whole team so that they could also become more productive. Once I had started using this library it had a snowball effect in that I found more and more pieces of code which I could convert into a library subroutine. This is now documented in Library of Standard Utilities. I took advantage of an addition to the language by writing Library of Standard COBOL Macros which allowed a single line of code to be expanded into multiple lines during the compilation process. Later on my personal programming standards were adopted as the company's formal COBOL Programming Standards.
While I did some COBOL programming on a UNIVAC 1100 mainframe followed by a Data General Eclipse, the vast majority of my work was done on a Hewlett Packard mini-computer using VIEW forms processing (later named to VPLUS) and the IMAGE database (later named to TurboIMAGE).
VPLUS forms operated with VDUs which operated in block mode. The screen had first to be designed and compiled using a separate program called FORMSPEC which kept these details in a separate disk file known as a forms file. Each screen/form was given a unique name and was comprised of text for labels and headings and fields for data. A field was a piece of text delimited by a pair of '[' and ']' characters into which the user could enter data. The delimiters could be made invisible on the screen if required. After this you went into the field editing menu which allowed you to define the properties of each field. The size was automatically limited to the number of characters between the '[' and ']' delimiters, but you could define a user-friendly field name, its data type and any processing rules.
Block mode meant that once a form/screen was displayed on the VDU the user was free to move the cursor around from field to field to enter data, but there would be no communication with the software until the ENTER key was pressed, at which point all the data would be sent as one contiguous block.
The Forms Management System which was available on HP mini-computers was called VIEW (later VPLUS) which could be accessed using the following set of intrinsics (system functions):
As it was often necessary to call a group of instrinsics, with error checking, to perform an operation I grouped these intrinsics into a series of wrapper functions which could be accessed using a collection of macros (pre-compiler directives) in order to cut down on the amount of typing.
Note that the calls to VGETBUFFER and VPUTBUFFER had to be hard-coded as each form required a separate definition of the data buffer to identify all the fields on that form. It was not possible to have a single call which would accept different buffers. If this buffer ever got out of step with the field definitions in the compiled form then the data would become corrupted.
In my early days it was common practice to build large programs which could handle several user transactions which used different forms, but this meant that the logic for each form and user transaction was mixed with the logic for other forms and user transaction in the same source file. However, there was a limit to the size that the program could use in memory, so the practice was to split the processing across several separate programs, such as one for customer details, a second for product details, and a third for order details. However, there was no method for sharing data between the different programs, so when building an order you had to look up the customer number in the customer program, look up the product id in the product program, then manually enter them into the order screen.
This situation was solved by separating the code into segments so only one segment was loaded into memory at a time. When code from another segment was required the current segment was swapped out to disk in order to make room for the new segment. Care had to be taken when deciding which piece of code went into what segment to minimise the amount of segment swapping. This then allowed the code for the customer, product and order programs to be assembled into a single executable program, and to pass around the customer id and product id in a global variable. I then decided to make each program less complicated by limiting each one to a single form and a single user transaction.
The standard database management system (DBMS) which was available on HP mini-computers was called IMAGE (later TurboIMAGE). This was a Network Database which had two basic types of table - a master and a detail. Unlike a Relational Database did not have an SQL interface. Instead it required the use of a set of function calls known as TurboIMAGE intrinsics, with a separate function for each operation, such as:
Calling these intrinsics was simplified by the provision of a set of macros (pre-compiler directives).
Note that the DBGET intrinsic could only read columns from a single dataset (table). The list argument was a comma-separated list of column names and the buffer argument was a composite data type in which the values for each of those columns would be placed. This means that JOINs to other tables were not possible.
In order to handle the data from a file - any file, be it database or non-database - it was necessary to define a record structure in the DATA DIVISION which defined its component parts and the sizes and types for each of those parts. When data was read in the entire structure was replaced in one go, so if there were any discrepancies between the physical structure of the record and its perceived structure in the software then some data corruption would occur. Because all data coming into the program, either from a screen or the database, was received in a predefined composite data type there was no need to include any code to perform type checking as the compiler would not allow any item to be updated with data of the wrong type.
By using standard code from a central library it made each programmer more productive as they had less code to write, and it eliminated the possibility of making some common mistakes. One of the common types of mistake that was eliminated was keeping the definition of certain data buffers, such as those for forms files (screens) and database tables, in line with their physical counterparts. This was taken care of with the COPYGEN utility which read the external definitions and generated text files which could then be added to a copy library so that the buffer definitions could be included into the program at compile time. Incorporating changes into the software therefore became much easier - change the forms file or database, run the COPYGEN utility, rebuild the copy library from the generated text files, then recompile all programs to include the latest copy library entries.
One of the first changes I made to what my predecessors had called "best practice" was to change the way in which program errors were reported to make the process "even better". Some junior programmers were too lazy to do anything after an error was detected, so they just executed a STOP RUN or EXIT PROGRAM statement. The problem with this was that it gave absolutely no indication of what the problem was or where it had occurred. The next step was to display an error number before aborting, but this required access to the source code to find out where that error number was coded. The problem with both of these methods was that any files which were open, and this included the database, the formsfile, any KSAM files any other disc files, which were not explicitly closed in the code would remain open. This posed a problem if a program failed during a database update which included a database lock as the database remained both open AND locked. This required a database administrator to logon and reset the database.
The way that one of my predecessors solved this problem was to insist that whenever an error was detected in a subprogram that instead of aborting right then and there that it cascaded back up the stack to return control to the starting program (where the files were initially opened) so that they could be properly closed. This error procedure was also supposed to include some diagnostic information to make the debugging process easier, but it had one serious flaw. While the MAIN program could open the database before calling any subprograms, each subprogram had the data buffers for each table that it accessed defined within its own WORKING-STORAGE section, but when that subprogram performed an exit its WORKING-STORAGE area was lost. This was a problem because if an error occurred in a subprogram while accessing a database table then the database system inserted some diagnostic information into that buffer, but when the subprogram returned control to the place from which it had been called then this buffer and the diagnostic information which it contained was lost, thus making the error report incomplete and virtually useless. This to me was unsatisfactory, so I came up with a better solution which involved the following steps:
This error report showed what had gone wrong and where it had gone wrong using all the information that was available in the communication areas. As it had access to the details for all open files it could close them before terminating. The database communication area included any current lock descriptors, so any locks could be released before the database was closed. Because of the extra details now included in all error reports this single utility helped reduce the time needed to identify and fix bugs.
As a junior programmer the standard practice for building software to maintain database tables was to create a single program to handle all the Create, Read, Update and Delete (CRUD) operations. This required the program to handle several different screens and required a mechanism which allowed the user to switch from one mode of operation to another. This was OK for simple tables without any relationships, but once you started to add child tables it increased the complexity by adding more operations which required more code and more screens. This increase in complexity also increased the number of bugs, so after a great deal of thought I realised that the only way to remove this complexity was to take the large and complex programs which performed multiple tasks and split them into small and simple programs which performed a single task each. This idea is documented in Component Design - Large and Complex vs. Small and Simple.
As well as reducing the number of bugs by reducing the complexity, this had an added bonus later on by making it easier to introduce Access Control at the user/transaction level as the necessary checking could be done within the framework BEFORE the application program was called instead of within the application program itself AFTER it had been called.
Originally all the error messages and function key labels were defined as strings of text, but it became a tedious exercise if that text needed to be changed. Fortunately the HP3000 operating system offered a facility known as a message catalog which allowed text to be defined in a disk file with an identity number so that the the program could supply a number and the system would automatically read the message catalog and convert the code number into text. This became incredibly useful when we were asked by one client to have these messages displayed in a different language as all we had to do was create a different version of the message catalog for each additional language.
Up until 1985 the standard method of building a database application which contained a number of different user transactions (tasks) was to have a logon screen followed by a series of hard-coded menu screens each of which contained a list of options from which the user could select one to be activated. Each option could be either another menu or a user transaction. Due to the relatively small number of users and user transactions there was a hard-coded list of users and their current passwords, plus a hard-coded Access Control List (ACL) which identified which subset of user transactions could be accessed by each individual user. This arrangement had several problems:
The above arrangement was thrown into disarray in 1985 when, during the design of a new bespoke application for a major publishing company, the client's project manager specified a more sophisticated approach:
I spent a few hours one Sunday in designing a solution. I started building it on the following Monday, and by Friday it was up and running. My solution had the following attributes:
The ability to jump to any transaction from any transaction presented a series of little problems which I had to solve one by one.
The first problem was to provide a way for the system administrator to configure the jump-to points for each transaction and to make these options visible to the user. For this I created a new database table called D-OTHER-OPTIONS with a set of maintenance screens. This would cause these options to appear in the function key labels at the bottom of the screen when the parent transaction was being run. To activate another transaction all the user had to do was press the relevant function key. Note that options on this list which the user was not able to access were automatically filtered out to make them invisible and non-selectable.
The second problem was memory consumption. Each subprogram had its own areas of memory it used which were defined in the DATA-DIVISION and the PROCEDURE-DIVISION, so when a new subprogram was called its memory requirements were added to those which were already in use. Unfortunately there was an upper limit to the size of each area, so if you chained too many CALLs, one after the other, you would exceed the memory limit and the program would abort. The only way to prevent this from happening was to exit the current program, thus releasing its memory, before calling the next one. This was the standard method which the user wished to avoid.
The third problem was to make this exit-then-call process invisible to the user. For this I devised a process which I called Transaction Auto Selection. This would load the identity of the selected transaction into MENU-AUTO-SELECT (part of COMMON-LINKAGE) before exiting the current transaction, thereby releasing all the memory which had been allocated to it. It would return control to the menu program which would spot a value in MENU-AUTO-SELECT which it would then activate. Easy Peasy Lemon Squeezy.
The fourth problem was that after running a new transaction the user would normally like to return to the previous transaction and have it resume from where it left off. In order to provide the identity of the previous transaction I had to maintain a pseudo hierarchy, a list of call statements, where the current transaction was always at the end of the list. New transactions could then be appended to this list. If the PREVIOUS TRAN function key was pressed the current transaction would be dropped off the end of the list, which converted the previous transaction into the current transaction which could then be restarted. If the EXIT function key was pressed then control would be returned to the first transaction in the list.
The fifth problem was when a transaction was restarted it did not automatically resume from where it left off, it started from the very beginning of its processing. To solve this I created a mechanism to Save and Restore screen contents so that before leaving the transaction it would save the pointers to the database record(s) on the current screen, and when being restarted it could rebuild the screen after reading the database using those pointers. This was possible because of my decision to have each transaction only be responsible for a single screen.
In the first version it was necessary for each new project to combine the relocatable binaries of this new framework with the relocatable binaries of their application subprograms in order to create a single executable program file. It was also necessary to append the project's VPLUS form definitions to the same disk file used by the framework. When I tried to separate the two forms files I hit a problem as the VPLUS software was not designed to have more than one file open in the same program at the same time. The solution was to design a mechanism using two program files, one for the MENU program and a second called MENUSON for the application, with data being passed between them using an Extra Data Segment (XDS) which is a portion of shared memory. After each application program was compiled it was linked with the MENUSON component in order to create an executable program file.
This framework was on top of a library of subroutines and utility programs which I developed earlier. This included a COPYGEN program which produced copylib members for both the IMAGE/TurboIMAGE database and the VIEW/VPLUS forms which helped reduce common coding errors by mistakes being made when altering the structure of a database table or a VIEW/VPLUS forms file and failing to update the appropriate data buffer correctly. Calling the relevant intrinsics (system functions) for these two pieces of software was made easy by the creation of a set of subroutines for accessing VPLUS forms plus a set of macros (pre-complier directives) for accessing the IMAGE database. All these documents are available on my COBOL page.
After that particular client project had ended, my manager, who was just as impressed with my efforts as the client, decided to make this new piece of software the company standard for all future projects as it instantly increased everyone's productivity by removing the need to write a significant amount of boilerplate code from scratch. This piece of software is documented in the following:
Another situation I was asked to deal with concerned the practice of some users to walk away from their monitors while it was still logged on to the application, which meant that some other person could use that terminal to do something which they shouldn't. The answer was to introduce a timeout value which would simulate the pressing of the EXIT key if here was no activity on the screen in the time specified.
This feature was later extended to include a System Shutdown facility. This allowed the system supervisor to issue a shutdown warning to all active users, and then to forcibly terminate their sessions if they had not logged off voluntarily.
Here I am referring to the movement to Reduced Instruction Set Computing (RISC) which was implemented by Hewlett-Packard in 1986 with its PA-RISC architecture. Interestingly they allowed a single machine to compile code which ran under the Complex Instruction Set Computing (CISC) architecture in what was known a "compatibility mode", or it could be compiled to run under the RISC architecture using "native mode". This required the use of a different COBOL compiler and an object linking mechanism as well as changes to some function calls. As a software house we had to service clients who had not yet upgraded their hardware to PA-RISC, but we did not want to keep two versions of our software.
This is where my use of libraries of standard code came in useful - I was able to create two versions of this library, one for CISC and another for RISC, which contained the function calls which were correct for each architecture. I then created two jobstreams to compile the application, one for CISC and another for RISC, which then took the same source code and ran the relevant compiler, library and linker to produce a program file for the desired architecture. This then hid all the differences from the developers who did not have to change their source code, but gave the client the right program for their machine.
More details can be found in The 80-20 rule of Simplicity vs Complexity.
While everybody else regarded this issue as a "bug" we developers saw it as an "enhancement" to a method that had worked well for several decades but which needed to be changed because of hardware considerations.
The origin of this issue was the fact that in the early days of computing the cost of hardware was incredibly expensive while the cost of programmers was relatively cheap. When I started my computing career in the 1970s I worked on UNIVAC mainframe computers which cost in excess of £1million each, and this meant that we had to use as few bytes as possible to store each piece of data. This meant that dates were usually stored in DDMMYY format, taking up 6 bytes, where the century was always assumed to be "19". It was also assumed that the entire system would become obsolete and rewritten before the century changed to "20".
In the 1980s while working with HP3000 minicomputers we followed the same convention, but as storing values in DDMMYY format made it tricky to perform date comparisons I made the decision, as team leader and database designer, to change the storage format to YYMMDD. The IMAGE database did not have an SQL interface, so instead of being able to sort records by date when they were selected we had to ensure that they were sorted by date when they were inserted. This required defining the date field as a sort field in the database schema.
Instead of storing YYMMDD dates using 6 bytes I thought it would be a good idea, as dates were always numbers, to store them as 4-byte integers, thus saving 2 bytes per date. That may not sound much, but saving 2 bytes per record on a very large table where each megabyte of storage cost a month's salary was a significant saving. This is where I hit a problem - the database would not accept a signed integer as a sort field as the location of the sign bit would make negative numbers appear larger than positive numbers. This problem quickly disappeared when a colleague pointed out that instead of using the datatype "I" for a signed integer I could switch to "J" for an unsigned integer. The maximum value of this field (9 digits) also allowed dates to be stored using 8 digits in CCYYMMDD format instead of the 6 digits in YYMMDD format. As I had already supplied my developers with a series of Date Conversion macros it was then easy for me to change the code within each macro to include the following:
IF YY > 50 CC = 19 ELSE CC = 20 ENDIF
This worked on the premise that if the YY portion of the date was > 50 then the CC portion was 19, but as soon as it flipped from 99 to 00 then the CC portion became 20.
This meant that all my software was Y2K compliant after 1986. The only "fix" that users of my software had to install later was when the VPLUS software supplied by Hewlett Packard, which handled the screen definitions, was eventually updated to display 8-digit dates instead of 6-digit dates.
In the 1990s my employer switched to a proprietary language called UNIFACE which is a Component-based and Model-driven language. It provided a richer Graphical User Interface (GUI) which included checkboxes, dropdown lists and radio buttons which were not available in FORMSPEC.
It was based on the Three Schema Architecture with the following parts:
UNIFACE was the first language which allowed us to access a relational database using the Structured Query Language (SQL). The advantage of UNIFACE was that we did not have to write any SQL queries as they were automatically constructed and executed by the Database Driver. The disadvantage of UNIFACE was that these queries were as simple as possible and could only access one table at a time. This meant that writing more complex queries, such as those using JOINS, was impossible unless you created an SQL View which could then be defined in the Application Model and treated as an ordinary table.
In UNIFACE you first defined entities in the built-in database known as the Application Model where an "entity" equated directly with a "database table". For each table you then defined the various fields (table columns) with their names, data types and sizes. You also identified which field(s) were in the primary key and which were in any candidate keys. You also defined any relationships between tables. The contents of the Application Model could then be exported to generate the CREATE TABLE scripts which could then be run in the DBMS to create the physical tables in the application database. Note that this did not create any foreign key constraints as all referential integrity was handled in the UNIFACE runtime.
Note that I reversed this process in my subsequent PHP implementation - I built the physical database first, then imported each table's structure into my own version of the Application Model which I called a Data Dictionary. Within this Data Dictionary I could edit the details to provide more information after which I could export them to a disk file called a table structure file which was loaded into each table object using standard code in the constructore of each concrete table class.
To create an online form you used the Graphical Form Painter (GFP), which was built into the Uniface Development Environment (UDE), to create form/report components which identified which entities and fields you wished to access. When using the GFP the whole screen is your canvas onto which you paint rectangles called frames, either an entity frame or a field frame. You then associate each frame with an object in the Application Model starting with an entity as shown in Figure 1. Inside each entity frame you can either paint a field from that entity or another entity frame for a different table, as shown in Figure 2. If you construct a hierarchy of entities within entities this will cause UNIFACE, when retrieving data, to start with the OUTER entity then, for each occurrence of that entity, use the relationship details as defined in the Application Model to retrieve associated data from the INNER entity. These two entities can be painted with the Parent entity first, as shown in Figure 3, or the Child entity first, as shown in Figure 4. After painting all the necessary entity and field frames the developer can then insert proc code into any of the entity or field triggers in order to add business logic. Default proc code which had been defined in the Application Model could then be either inherited or overridden in any form component.
| This will show the data for a single occurrence. |
|
| This will show the data for a multiple occurrences. |
")
|
| This shows two entities in a parent-child relationship. There is one OUTER occurrence of the parent and multiple INNER occurrences of the child.
This will require two SQL queries, one for the OUTER and one for the INNER. |
")
|
| This shows two entities in a parent-child relationship. There are multiple OUTER occurrence of the child and a single INNER occurrence of each parent. Note that each INNER could be a different row.
Note that with UNIFACE each entity would have to be read separately, which leads to the N+1 problem. With PHP the two tables could be read in a single query on the OUTER table which includes a JOIN to the INNER table. |
")
|
Just as in COBOL which used FORMSPEC, all the forms/screens used in UNIFACE had to be designed and then compiled using a special piece of software known as the Graphical Form Painter (GFP) which extractd data from the Application Model. This meant that each screen knew the datatype for each field on the screen, so it would not accept any invalid values. Unlike in COBOL where the compiled forms were stored in a separate file, which meant that you had to access the contents of this file by calling a number of different intrinsics (functions) from within your code, with UNIFACE you actually ran the compiled form component. This then displayed the form as it had been designed, and used icons/buttons in the menu bar to perform operations such as RETRIEVE and STORE. As the datatype of each field had been specified when the form was designed it was therefore impossible to input a value of the wrong type. If in your code you tried to overwrite any value with another value of the wrong type then the form would fail when you tried to compile it.
After I had learned the fundamentals of this new language I rebuilt my development framework. I first rebuilt the MENU database, then rebuilt the components which maintained its tables. After this I made adjustments and additions to incorporate the new features that the language offered. This is all documented in my User Guide.
I started with UNIFACE Version 5 which supported a 2-Tier Architecture with its form components (which combined both the GUI and the business rules) and its built-in database drivers. UNIFACE Version 7 provided support for the 3-Tier Architecture by moving the business rules into separate components called entity services, which then allowed a single entity service to be shared by multiple GUI components. Each entity service was built around a single entity (table) in the Application Mode, which meant that each entity service dealt with a single table in the database. It was possible to have code within an entity service which accessed other database tables by communicating with those table's entity services. Data is transferred between the GUI component and the entity service by using XML streams. That new version of UNIFACE also introduced non-modal forms (which cannot be replicated using HTML) and component templates. There is a separate article on component templates which I built into my UNIFACE Framework.
Whilst my early projects with UNIFACE were all client/server, in 1999 I joined a team which was developing a web-based application using recent additions to the language. Unfortunately this was a total disaster as their design was centered around all the latest buzzwords which unfortunately seemed to exclude "efficiency" and "practicality". It was so inefficient that after 6 months of prototyping it took 6 developers a total of 2 weeks to produce the first list screen and a selection screen. Over time they managed to reduce this to 1 developer for 2 weeks, but as I was used to building components in hours instead of weeks I was not impressed. Neither was the client as shortly afterwards the entire project was cancelled as they could see that it would overrun both the budget and the timescales by a HUGE margin. I wrote about this failure in UNIFACE and the N-Tier Architecture. After switching to PHP and building a framework which was designed to be practical instead of buzzword-compliant I reduced the time taken to construct tasks from 2 weeks for 2 tasks to 5 minutes for 6 tasks.
I was very unimpressed with the way that UNIFACE produced web pages as the HTML forms were still compiled and therefore static. When UNIFACE changed from 2-Tier to 3-Tier it used XML forms to transfer data between the Presentation and Business layers, and the more I investigated this new technology the more impressed I became. I even learned about using XSL stylesheets to transform XML documents, but although UNIFACE had the capability of performing XSL transformations it was limited to transforming one XML document into another XML document but with a different format. When I learned that XSL stylesheets could actually be used to transform XML into HTML I did some experiments on my home PC and I became even more impressed. I could not understand why the authors of UNIFACE chose to build web pages using a clunky mechanism when they had access to XML and XSL, which is why I wrote Using XSL and XML to generate dynamic web pages from UNIFACE.
I wrote about this earlier in My career history - Another new language.
I could see that the future lay in web applications, but I could also see that UNIFACE was nowhere near the best language for the job, so I decided to switch to something more effective. I decided to teach myself a new language in my own time on my home PC, so I searched for software which I could download and install for free. My choices quickly boiled down to either Java or PHP. After looking at sample code, which was freely available on the internet, I decided that Java was too ugly and over-complicated and that PHP was simple and concise as it had been specifically designed for writing database applications using dynamic HTML.
I did not go on a course on how to become a "proper" OO programmer (whatever that means), instead I downloaded everything I needed onto my home PC, read the PHP manual, looked through some online tutorials and bought a few books. I knew nothing about any so-called "best practices" such as the SOLID and GRASP principles, nor about Design Patterns, so I just used my 20 years of previous programming experience, my intellect and my intuition to produce the best results that I possibly could. I gauged my success on the amount of reusable code which I produced which contributed directly to my huge gain in productivity.
In order to make the transition from using a procedural language to an object oriented one I needed to understand the differences. They are similar in that they are both concerned with the writing of imperative statements which are executed in a linear fashion, but one supports encapsulation, inheritance and polymorphism while the other does not, as explained below:
| Procedural | Object Oriented |
|---|---|
| You could define data structures in a central copy library and refer to it in as many programs or subprograms as you liked. I wrote a COPYGEN program which could read the data structures from the database or the formsfile and automatically produce COPYLIB entries. | There is no built-in equivalent of a copy library. PHP does not use rigid data structures, it uses dynamic arrays which are infinitely flexible. |
| You could put reusable code into a subprogram, with its separate DATA DIVISION and PROCEDURE DIVISION, and then call that subprogram from as many places as you liked. The problem was that when the "call" ended all working storage in the DATA DIVISION was lost. | ENCAPSULATION means that you can define a class containing as many properties (data variables) and methods (functions) as you like, and then instantiate that class into as many objects as you like. After calling a method on an object the object does not die, nor is its internal data lost. You can keep calling methods to either read or update its internal data, and that data will remain available until the object dies. |
| There is no inheritance. | INHERITANCE means that after defining a class you can create another class which "extends" (inherits from) the first class. In this structure the first class is known as a "superclass" while the second is known as a subclass. Both may contain any number of properties and methods. When the subclass is instantiated into an object the result is a combination of both the superclass and the subclass. The subclass may add its own set of extra properties and methods, or it may override (replace) those defined in the superclass. |
| There is no polymorphism. A function name can only be defined once in the entire code base, so it is not possible for the same function name to be used in multiple subprograms.This means that each function has a fixed implementation. | POLYMORPHISM means that the same method name can be defined in many classes, each with its own implementation. It is then possible to write code which calls a method on an unspecified object where the identity of that object is not specified until runtime. This is known as Dependency Injection. |
Another major difference concerned the construction of the screens in the user interface. In my previous languages it required the use of a separate program - FORMSPEC in COBOL and Graphical Form Painter (GFP) in UNIFACE - to design and then compile each screen. PHP is simpler because the user interface is an HTML document which is not compiled, it is nothing more than a large string of text containing a mixture of HTML tags and data values. PHP has a large collection of string handling functions which enable the text file to be output (using the echo statement) in fragments during the script's execution, but this requires the use of output buffering if you want to use the header() function to redirect to another script. An alternative would be to use some sort of templating engine which would construct and output a complete HTML document as a final act before the script terminates. No special code is necessary to receive HTTP requests as the data is automatically presented in either the $_GET or $_POST array.
Switching from one programming language to another means that you have to recognise and then deal with the differences. My first switch from COBOL to UNIFACE was relatively easy as they were similar, but switching to PHP was totally different. The similarities and differences are highlighted in the following table:
| COBOL | UNIFACE | PHP | |
|---|---|---|---|
| Paradigm | Procedural | Component-based | Object Oriented |
| Editor | Text | IDE | Text or IDE |
| Compiled | Yes - separately | Yes - within IDE | No - interpreted |
| Structs | Yes | Yes | No - dynamic arrays |
| Statically Typed | Yes | Yes | No - dynamic |
| Compiled screen | Yes - using FORMSPEC | Yes - using Graphical Form Painter | No - HTML |
| database data | record (struct) | struct | dynamic arrays |
| program data | stateful | stateful | stateless |
COBOL and UNIFACE were both compiled - with COBOL the source editing and compiling were done in separate programs, while with UNIFACE they were both done within the Uniface Development Environment (UDE).
COBOL and UNIFACE both used screens which were designed using special software and then compiled. At run time the compiled screen was referenced, and the data was sent back and forth using a struct (also known as records or composite data types). This caused them to be statically typed as each field's type had to be defined within the struct, and this also meant that no field could be overwritten with a value of the wrong type, nor could its type be changed.
COBOL and UNIFACE both used structs for reading database data.
With COBOL the structs used in the program source had to be defined manually, which sometimes lead to errors, while with UNIFACE each field's datatype was extracted automatically from the built-in Application Model.
The biggest differences between PHP and my earlier languages are as follows:
The significant difference is that PHP cannot use predefined structs for the transfer of data between itself and the client device and between itself and the database as neither the HTTP or SQL protocols use structs. The HTML document which is sent to the client device is a file containing nothing but one long string of text, and when a request is received from an HTML document all the values are returned in $_POST, which is an array of strings. When a SQL query is sent to the database that query is one long string of text, and when a response is returned all the values are presented in an array of strings. Arrays can therefore be regarded as dynamic structures as they can be built on the fly using values of any type.
Unlike a struct where the contents are predefined and fixed, which means that each screen or database table requires its own structure definition, for PHP both the outgoing and incoming data streams are dynamic. The outgoing HTML documents and SQL queries are both strings of text containing both labels and data while the incoming data appears as an associative array of field names and their associated values. The contents of an array does not have to be predefined therefore it is dynamic.
While the type of an element in a struct cannot be changed, which can be detected and reported at compile time, every element within a PHP array can have its type changed at anytime, and any type mismatch can only be detected at run-time. This does not (or should not) matter to PHP as it was designed so that scalars auto-convert depending on the context, thus making any manual conversion totally redundant. This behaviour is documented in RFC: Strict and weak parameter type checking.
If you look at the example of loose coupling you should see that the statement $dbobject->insertRecord($_POST); will work for any database table with whatever data is contained in the $_POST array. Note that the contents of this array will always be validated against the $fieldspec array within the object, and if any error is detected the insert will not be performed. Instead the user will be shown an error message and given the opportunity to correct the error.
Compiled languages which use predefined and static structures can be statically typed simply because external data will always be loaded into one of these predefined structures, so each data item will automatically have the type as it was defined in that structure. Any attempt to write code which tries to overwrite a data item with a value of the wrong type will fail at the compilation phase. Likewise if you use a data item as an argument on a function call, and that function expects a value of a different type then this can also be detected and rejected at the compilation phase.
PHP, on the other hand, does not use predefined and static structures as neither the HTTP nor SQL protocols support their use. Data is sent out as one long string of text, either as an HTML document or an SQL query string, and data comes in as a dynamic array where all the values are strings. Refer to $_POST and either mysql_fetch_assoc() or mysqli_fetch_row() for details. The only difference is that the database may return NULL values whereas an HTML form will return an empty string instead.
In PHP it is not necessary to convert any value from its original "string" type to another type before it can be used. This is because PHP's type system was designed from the ground up so that scalars auto-convert depending on the context. This means that if you pass a string to a function that expects an integer then PHP will use its type juggling capabilities to convert that value into the correct type. Note that this conversion will only happen within the function, the original value will not change its type. This behaviour is documented in RFC: Strict and weak parameter type checking which says:
Strict type checking is an alien concept to PHP. Type checking puts the burden of validating input on the callers of an API, instead of the API itself. Since typically functions are designed so that they're called numerous times - requiring the user to do necessary conversions on the input before calling the function is counterintuitive and inefficient. It makes much more sense, and it's also much more efficient - to move the conversions to be the responsibility of the called function instead.
The only time that type juggling would fail was if a value contained characters that were inconsistent with the expected type. Thus the string "123.45" can be coerced into a number while "10 green bottles" cannot. It is therefore incumbent on the programmer to check the validity of all user input at the earliest possible opportunity. Anyone who fails to do so has only themselves to blame. Their incompetence is not the fault of the language, it is theirs and theirs alone. All the tools are there, they just have to learn to use them.
This automatic coercion worked well in PHP up until version 8.1 when the core developers introduced a massive BC (Backwards Compatibility) break by deprecating the passing of NULL to parameters of any internal functions. Their argument for this BC break was given in PHP RFC: Deprecate passing null to non-nullable arguments of internal functions as:
Internal functions (defined by PHP or PHP extensions) currently silently accept null values for non-nullable arguments in coercive typing mode. This is contrary to the behavior of user-defined functions, which only accept null for nullable arguments. This RFC aims to resolve this inconsistency.
What these morons had failed to consider was that a change in version 7.1 allowed any argument in a user-defined function to be marked as nullable, thus aligning them with the behaviour of internal functions. The core developers then had the choice of two options:
One of these options creates a massive BC break for all userland developers. The other creates a massive amount of work to update every internal function in the manual. They chose the option which creates the least amount of effort on their part but a massive amount of effort for all userland developers. This is why I wrote The PHP core developers are lazy, incompetent idiots.
In my previous decades of experience I had designed and built multiple applications which contained numerous database tables and user transactions, so I had lots of practice at examining those components looking for similarities as well as differences. If the similarities can be expressed as repeatable patterns, either in behaviour or structure, and those patterns can be turned into code, then it should be possible to build applications at a faster rate by not having to spend so much time in duplicating the similarities. While is true that every subsystem uses different data which is subject to different business rules the software used to process that data has a large number of similarities:
Smart data structures and dumb code works a lot better than the other way around.
In a large ERP application, such as the GM-X Application Suite, which is comprised on a number of subsystems, each subsystem has a unique set of attributes:
Despite the fact that these two areas are completely different for each subsystem, they each have their own patterns and so can be handled using standard reusable code provided by the framework:
Note that each user transaction can be generated from a function within the Data Dictionary by combining a table class (Model) with a Transaction Pattern, which combines a particular Controller with a particular View.
I started by building a small prototype application as a proof of concept (PoC). This used a a small database with just a few tables in various relationships - one-to-many, many-to-many, and a recursive tree structure. I then set about writing the code to maintain the contents of these tables. As a follower of the KISS principle I started with the basic functionality and and added code to deal with any complexities as and when they arose.
For the first database table I creating a single Model class, without using any inheritance, which contained the following:
insertProduct() and InsertOrder(). It was obvious to me that unique method names could not be shared and reused whereas common method names could. Each of these methods was broken down into a series of separate steps, as shown in common table methods.take this array of data items and build me a query.
I then created a set of scripts for the Presentation layer which performed a single task each, just as I had done in my COBOL days. This then resulted in a group of scripts such as those shown in Figure 5
Figure 5 - A typical Family of Forms
")
Note that each of the objects in the above diagram is a hyperlink.
In this arrangement the parent screen can only be selected from the menu bar while the child screens can only be selected from the navigation bar which is specific to that parent.
Each of these scripts is a separate Controller which performs a single task (user transaction). They access the same Model, but each calls a different combination of the common table methods, plus any local "hook" methods, in order to achieve the desired result. Each can only produce a single output (View) which is returned to the user.
As I had already decided to build all HTML documents using XSL transformations I built a View using a group of functions to carry out the following at the very end of the script after all the processing in the Model(s) had been completed:
In my prototype these were available as a collection of separate functions, but later on I turned them into methods within a View object.
I hit a problem when I converted the contents of the $_POST array into an SQL INSERT query as it did not recognise the entry for the submit button as a valid column name, which caused the query to fail. I needed to edit the contents of this array to remove any names which did not exist in that table. I got around this problem initially by creating a class property called $fieldlist which I manually populated in the class constructor with a list of valid column names. I then modified the code which built the SQL query to filter out anything in $fieldarray which did not also exist in the $fieldlist array.
I then realised that if I did not validate the contents of $fieldarray before passing it to the query builder it would cause a problem if a column's value did not match that column's specifications. I started to manually insert code to validate each column one at a time, but then I realised that columns with the same data type required the same validation code and the same error message. Instead of repeating this similar code over and over again I decided to replace the $fieldlist array, which was just a list of field names, with the $fieldspec, which is a list of field names and their specifications. This then allowed me to create a standard validation object which required two input variables - $fieldarray and $fieldspec. The output from this object is an array of error messages, with the field/column name as the key and the message as the value. An empty array means no errors, but there could be numerous error messages for several fields.
After finishing the code for the first table I then created the code for the second table. I did this by copying the code and then changing all the table references, but this still left a large amount of code which was duplicated. In order to deal with this I created an abstract class which I then inherited from each table class. I then moved all the code which was duplicated from each table class into the abstract class, and when I had finished each class contained nothing but a constructor as all processing was inherited from the abstract class.
Note that what I did *NOT* do was to inherit from the first concrete class for table#1 to create another concrete class for table#2. Why not? Because I could see that class#1 contained information that needed to be changed in class#2, that information being the table's structure. I also knew that if I added some unique processing into class#1 which I did not want to be shared with other classes then it would create problems. This is precisely why I created an abstract class which contained only those methods which I wanted to be shared. This is also why I avoided the problems encountered by other programmers which caused them to say favour composition over inheritance.
Years later I discovered that this approach had already been recommended in a paper called Designing Reusable Classes which was published as long ago as 1988 by Ralph E. Johnson & Brian Foote which can be summarised as follows:
Abstraction is the act of separating the abstract from the concrete, the similar from the different. An abstraction is usually discovered by generalizing from a number of concrete examples. This then permits a style of programming called programming-by-difference in which the similar protocols can be moved to an abstract class and the differences can be isolated in concrete subclasses.
I discuss this paper in more detail in The meaning of "abstraction".
I still had duplicate Controller scripts, but I noticed that the only difference between them was the hard-code table (Model) name. I quickly discovered that I could replace the following code:
require "classes/foobar.class.inc"; $dbobject = new foobar;
with the following alternative:
require "classes/$table_id.class.inc"; $dbobject = new $table_id;
This then enabled me to supply the missing information from a separate component script which resembles the following:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
Each task in the application has its own version of this script. The View component is a screen structure script.
While the framework can take care of all standard processing there will always be times when you will want to perform some additional processing or data validation that cannot be performed automatically. The standard processing flow is handled by the methods in the abstract table class, so what is needed is a mechanism where you can say "when you get to this point in the processing flow I want you to execute this code". This is where my use of an abstract table class provided a simple and elegant solution. My experiments with inheritance had already proved to me that when you inherit from one class (the superclass) into another (the subclass) the resulting object will contain the methods from both classes. The method in the superclass will be executed unless you override it in the subclass. This means that in certain points of the processing flow I can call a method which is defined in the superclass but which does nothing, but if I want to I can copy that method into my subclass and insert whatever code is necessary. This then replaces at runtime a method in the superclass which does nothing with a method in the subclass which does something. To make it easy to identify such methods I gave them a "_cm_" prefix which stands for customisable method. Some of them also include "pre_" or "post_" in the prefix to identify that they are executed either before or after the standard method of that name. Some examples can be found at How do you define 'secondary' validation?
It wasn't until many years later that I discovered that what I had done was known as the Template Method Pattern and that my customisable methods were actually called "hook" methods.
In a relational database it is highly likely that some tables will be related to other tables in what is known as a one-to-many or parent-child relationship. This relationship is identified by having a foreign key of the child table which points to the primary key of an entry on the parent table. An entry on the parent table can be related to many entries on the child table, but a child can only have a single parent. Note that a one-to-one relationship can be defined by making the definition of the foreign key the same as the child's primary key.
Where a parent-child relationship exists it is often necessary to go through the parent before being able to access its children. To deal with this situation I emulated the practice I had encountered in UNIFACE which was to create a form component which accessed both tables as shown in Figure 3. In this structure the parent/outer entity is read first, and the relationship details which have been defined in the Application Model are used to convert the primary key of the parent into the foreign key of the child. To do this in PHP all I had to do was construct a new Controller which accessed two Model classes in the same sequence. Some programmers seem to think that a Controller can only access a single Model, or that relationships should be dealt with using Object Associations, but as I had never heard of these "rules" I did what I thought was the easiest and most practical.
The same 2-Model Controller, as described in the LIST2 pattern, can also be used even if you have a hierarchy of parent-child relations as you never create a single task or a single object to manage the entire hierarchy, you have a separate task to deal with each individual parent-child relationship. It is the Controller for that task that manages the communication between the parent and child entities, not any code within those entities. In order to navigate your way up and down the hierarchy you can start with the task which manages the pair of related tables at the top, then, after selected a child row on that screen you press a navigation button which activates a different task which shows that child row as the parent and a set of child rows from a different table.
This prototype application, which I published in November 2003, had only a small number of database tables with a selection of different relationships, but the code that I produced showed how easy it was to maintain the contents of these tables using HTML forms. Although it had no logon screen, no dynamic menus and no access control, it did include code to test the pagination and scrolling mechanism, and the mechanism of passing control from one script to another and then back again.
As I had seen the benefits of the 3 Tier Architecture during my work with UNIFACE I decided to adopt the same architecture for PHP. This was made easy as programming with objects automatically forces the use of two separate objects - one containing methods and another to call those methods. This architecture has all database access carried out in a separate object which contains APIs for a specific DBMS, as shown in Figure 6 below.
Figure 6 - Requests and Responses in the 3 Tier Architecture
")
This allows, in theory, an object in any one of the layers to be swapped with a similar object with a different implementation without having an effect on any of the objects in the other layers. For example, the object in the Data Access layer can be swapped with another in order to access a different DBMS. This came in useful when MySQL version 4.1 was released as it had the option of using a different set of "improved" APIs. Some programmers claim that this functionality is rarely used because once an organisation has chosen a DBMS it is unlikely to switch to an alternative. These people are short sighted as they are not considering the phrase "once chosen". My framework is used by others to build their own applications, so I allow them to choose which DBMS they would prefer to use before they start building their application.
I later discovered that as a consequence of splitting my Presentation layer into two separate objects - a Controller and a View - I had in fact implemented a version of the Model-View-Controller (MVC) design pattern. This uses the structure shown in Figure 7 below:
Figure 7 - The basic MVC relationship
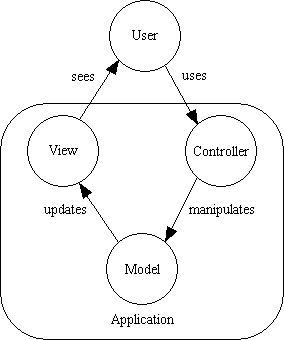
Note that in my implementation the Model does not send its changes to the View. When the Model(s) have finished their processing the Controller injects them into the View which then sucks out the data using a single call to the getFieldArray() method. The View will then rebuild its output entirely from scratch.
This combination of the two architectural patterns causes one to overlap with the other, as shown in Figure 8 below:
Figure 8 - The MVC and 3-Tier architectures combined
")
An alternative diagram which shows the same information in a different way is shown in Figure 9 below::
Figure 9 - MVC plus 3 Tier Architecture combined
")
Note that each of the above boxes is a hyperlink which will take you to a detailed description of that component.
A more detailed diagram which includes all the software components is shown in Figure 10.
Figure 10 - Environment/Infrastructure Overview
")
Note that each of the above numbered boxes is a hyperlink which will take you to a detailed description of that component.
My prototype application was very basic as it allowed the user unrestricted access to all of its components, but it was missing the following:
My next step was to take my old MENU database and construct a new version using MySQL. This started off with just the following tables:
I then built or modified the following components:
Following on from my previous experience I knew that a system is actually made up of a number of subsystems which should be integrated as much as possible so that they can share data. For example, you don't want a CUSTOMERS table in the ORDER subsystem and a separate CUSTOMERS table in the INVOICE subsystem and the SHIPMENT subsystem - it would be much more efficient to have the data stored once so that it can be shared instead of being duplicated. Rather than have the components for each subsystem all mixed together in the place I decided to keep then separate as much as possible so that I could add (or even remove) subsystems without having too much effect on other subsystems. To accomplish this I decided on the following:
In this way it is possible to create a new subsystem on one machine, zip up the contents of its subsystem directory, copy that zip file to another machine with a RADICORE installation, then import the details into that installation so that it can be run on that second machine. This facility is demonstrated on the Prototype Applications page which allows a collection of sample applications to be loaded into any RADICORE installation.
While working on the prototype, and later the framework, I encountered several problems which I eliminated with a little refactoring.
To mirror the message catalog which I created in my COBOL days I created files to hold text in different languages which are accessed using the getLanguageText() and getLanguageArray() functions. These are now part of my Internationalisation feature.
To mirror the error handler which I created in my COBOL days I created a version for PHP.
Instead of being forced to use a separate screen for entering search criteria I added a QuickSearch area into the title area of all LIST screens.
Like in all my software endeavours I start by writing things out in long-hand, then look for repeating patterns which I can move to some sort of reusable library. Anybody who is familiar with HTML knows that there is a fixed set of input controls each of which uses a fixed set of HTML tags, so it would be useful to output each set of tags using a reusable routine. With XSL you can define a named template which you can call using <xsl:call-template>. You can either define a template within the stylesheet, or you can put it in a separate file which you can <xsl:include>.
I started off by creating a separate XSL stylesheet for each different screen so that I could identify which element from the associated XML document went where, and with what control. After a while I found this rather tedious, so I did a little experimenting to see if I could define the structure I wanted within the XML document itself, then get the XSL stylesheet to build the output using this structure. With a little trial and error I got this to work, so my next task was to define this structure in a customisable PHP script which could then be copied into a corresponding <structure> element within the XML document. Originally I created each of the PHP scripts by hand, but after I built my Data Dictionary I built a utility to generate them for me.
This meant that I no longer had to manually construct a separate XSL stylesheet for each screen with its unique list of data elements as I could now supply that list in a separate file which could then be fed into a small number of reusable stylesheets. When I say "small" I mean a library of just 12 stylesheets and 8 sets of templates. I have used this small set of files to create a large ERP application with over 4,000 different screens, which represents a HUGE saving in time and effort.
This is discussed in more detail in Reusable XSL Stylesheets and Templates.
What is a transaction? This term is short for user transaction. It identifies a task that a user may perform within an application. Some complex tasks may require the execution of several smaller tasks in a particular sequence. Some of these user transactions may include a database transaction. In the RADICORE framework a task is implemented using a combination of different components - A Controller, one or more Models, and an optional View. Each task has its own component script which identifies which combination of those components will be required to process that task.
What is a pattern? It is a theme of recurring elements, events or objects, where these elements repeat in a predictable manner. It can be a template or model which can be used to generate things or parts of a thing. In software a pattern must be capable of being defined in a piece of code which can be maintained in a central library so that the pattern can be referenced instead of being duplicated. The avoidance of duplication is expressed in the Don't Repeat Yourself (DRY) principle.
What is a Transaction Pattern? It is a method of defining a matched pair of pre-written and reusable Controllers and Views which can be linked with one or more different Models in order to provide a working transaction. This provides all the common boilerplate code to move data between the User Interface (UI) and the database, and allows custom business logic to be added to individual Model classes using "hook" methods.
Why is it different from a Design Pattern? A design pattern is nothing more than an outline description of a solution without any code to implement it. Each developer has to provide his own implementation, and it is possible to implement the same pattern many times, each with different code. A design pattern has limited scope in that it can only provide a small fragment of a complete program, so several different patterns have to be joined together in order to produce a working program. Conversely each Transaction Pattern uses pre-written components which makes it possible to say combine Pattern X with Model Y to produce Transaction Z
and the end result will be a working transaction. Another difference is that Design Patterns are invisible from the outside as you cannot tell what patterns are embedded in the code when you run the software. This is not the case with Transaction Patterns as simply by observing the structure of the screen and understanding the operations that the user can perform with it you can determine which Pattern was used.
Note that there is currently only one set of components which implement these Transaction Patterns, and these are built into the RADICORE framework
After having personally developed hundreds, if not thousands, of user transactions which performed various CRUD operations on numerous database tables using numerous different screens I began to see some patterns emerging. This caused me to examine all these components looking for similarities and differences with a view to making reusable patterns for those similarities as well as a way to isolate the differences. My investigations, which are documented in What are Transaction Patterns, led me to identify the following categories:
This can be boiled down into the following:
I noticed that different combinations of structure and behaviour were quite common, so I created a different pattern for each which is now documented in Transaction Patterns for Web Applications. All you have to do to create a working transaction is to combine a pattern with a Model.
Each user transaction is comprised of a combination of the components shown in Figure 9. The following reusable components are pre-built and supplied by the framework:
The following components are built by the application developer, originally by hand, but now using functions within the Data Dictionary:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>As you can see it does nothing but identify which Model is to be combined with which View and which Controller. Each URL points directly to one of these scripts on the file system, thus avoiding the need for a front controller.
Each transaction also requires the following database updates:
Initially each of the above disk files had to be created manually, but after I built my Data Dictionary I built components into the framework to generate them for me. I can now create working transactions in a short period of time simply by pressing a few buttons, and this has contributed greatly to my increase in productivity.
Originally I created the table class files, table structure files, component scripts and screen structure scripts by hand as they were so small and simple, but after doing this for a while on a small number of tables and with the prospect of many more tables to follow I realised that the entire procedure could be speeded up by being automated. Where UNIFACE had an internal database known as an Application Model to record the structure of all the application databases I created my own version which I called a Data Dictionary. However, I changed the way that it worked:
In this way I do not have to access the Data Dictionary from within a table object in order to extract the information which I need as it has already been extracted and placed in a disk file. The contents of this file are loaded into the object's common table properties when the loadFieldSpec() method is called in the class constructor.
If the structure of any table is changed the process of making these changes available to the table objects is very simple and straightforward:
Note that UNIFACE allowed default trigger code to be defined in the Application Model which would be automatically "inherited" when an entity was copied into a form/service component, but no further inheritance was possible.
Note that when a table's information is exported from the Data Dictionary it is only the table structure file which will be overwritten so as not to lose any custom code which has been inserted into any of the "hook" methods.
While the objectives may have been the same, the way in which those objectives were implemented was totally different, with my PHP implementation being much faster. While it took some effort and ingenuity to build the PHP implementation, I considered this effort to be an investment as it reduced the time taken to generate table classes and the tasks needed to maintain the contents of those tables. This is why I was able to create my first ERP package containing six databases in just six months - that's one month per database.
In May 2004 I published A Role-Based Access Control (RBAC) system for PHP which described the access control mechanism which I had built into my framework. This provoked a response in 2005 when I received a query from the owner of Agreeable Notion who was interested in the functionality which I had described. He had built a website for a client which included a number of administrative screens which were for use only by members of staff, but he had not included a mechanism whereby access to particular tasks could be limited to particular users. He had also looked at my Sample Application and was suitably impressed. Rather than trying to duplicate my ideas he asked if he could use my software as a starting point, which is why in January 2006 I released my framework as open source under the brand name of RADICORE.
Unfortunately he spent so much time in asking me questions on how he could get the framework to do what he wanted that he decided in the end to employ me as a subcontractor to write his software for him. He would build the front-end website while I would build the back-end administrative application. I started by writing a bespoke application for a distillery company which I delivered quite quickly, which impressed both himself and the client. Afterwards we had a discussion in which he said that he could see the possibility of more of his clients wanting such administrative software, but instead of developing a separate bespoke application for each, which would be both time consuming and costly, he wondered if I could design a general-purpose package which would be flexible enough so that it could be used by many organisations without requiring a massive amount of customisations. This was the start of a collaboration between my company RADICORE and his.
This package was given the name TRANSIX, which was derived from the name of another company he owned called Transition Engineering.
I knew from past experience that the foundation of any good database application is the database itself, and that you must start with a properly normalised database and then build your software around this structure. This knowledge came courtesy of a course in Jackson Structured Programming which I took in 1980. I had recently read a copy of Len Silverston's Data Model Resource Book, and I could instantly see the power and flexibility of his designs, so I decided to incorporate them into this ERP software. I started by building the databases for the following subsystems:
After building each of these databases I then imported their table structures into my Data Dictionary from which I created the class file for each table. Then I created the starting transactions for dealing with those tables. The framework allowed me to quickly develop the basic functionality of moving data between the user interface and the database so that I could spend more time writing the complex business rules and less time on the standard boilerplate code. Adding the business rules involved inserting the relevant code into the relevant "hook" methods as discussed in Adding custom processing.
I started building this application in 2007, and the first prototype was ready in just 6 man-months. If you do the maths you will see that this meant that I took an average of only one man-month to develop each of those subsystems. It took a further 6 months to integrate them into a working website for an online jewellery company as I had to migrate all the existing data from its original database into the new database, then rewrite the code in the front-end website to access the new database instead of the old one. I also added in some new features that they had asked for, such as giving customers the ability to order sample rings, and to be able to sell returned rings from inventory. This went live in May 2008 and enabled the company to triple their turnover to £2.5m within 4 years without adding to their cost base, so I would call that a success.
Later on I added the following subsystems:
I have often been told by my critics that because I am not following their ideas on what constitutes "best practices" that my work must surely be bad, and if it's bad then it must surely be unmaintainable. As is usual their theories fall short when it comes to practice. As well as being the author of the framework I have also used this framework to build a large ERP application which contains over 20 subsystems.
Sometimes a new requirement comes along which can only be satisfied with a new subsystem, sometimes it means amending an existing subsystem, and sometimes it means amended the framework so that the new feature is available to all subsystems. Among the changes I have made to the framework are:
One of the features I added to my UNIFACE framework was an Audit Log which captured the changes made to any database tables and stored them in a standard set of audit tables which could then be interrogated with a single set of screens. I managed to add the same facility to my PHP framework, as detailed in Creating an Audit Log with an online viewing facility, but, as expected, it required a totally different implementation.
After creating a separate AUDIT database with a small set of tables the next step was to insert the code to store data in these tables following any INSERT, UPDATE or DELETE operation. This was made incredibly easy as every one of those operations is executed by corresponding INSERT, UPDATE and DELETE methods in each of my Data Access Objects. It was therefore a straightforward process to modify each of these methods to identify which columns were affected on which table and to write these details to the AUDIT database.
For this I created the following transactions using standard Transaction Patterns.
Shortly after creating my TRANSIX application it was suggested that a Workflow module would be a useful addition to the framework. I was pointed to an article on Petri Nets for inspiration. I looked at the components of a Petri Net - Places, Transitions, Arcs and Tokens - and noticed straight away that Transitions represented tasks or activities. That meant that there was a one-to-one relationship between transitions in a Petri Net and transactions (tasks) in my MENU database.
I created a simple Workflow database which has two parts:
Step #1 was to develop the maintenance screens for each of these tables. This was relatively simple, with the only tricky part being the definition of the validation rules which had to be passed before a workflow could be activated.
Step #2 was recognising that the execution of a task required the creation of a new workflow case. As this can only be done after a new record has been added to a database table, which is performed by a task which uses the insertRecord() method, it was easy to insert some new code into my abstract table class after an INSERT operation had been successfully processed. Once a workflow case has been started a token will be created on the start place.
Step #3 was recognising that the current task being run is part of an open workflow case. If that task completes successfully then one token is removed from each if its input places and one token is added to each of its output places. The creation of a token may enable a new transition.
You should note that the application developer does not have to write any code to make any transaction part of a workflow. A task is only included in a workflow case when its task_id appears in the definition of a workflow. All further processing is carried out by code within the abstract table class which is inherited by every concrete table (Model) class.
In the original design all HTML pages produced by the framework were suitable for full-size displays, but with the advent of devices with smaller screens, such as tablets and mobile phones, the demand to have those pages readable on those devices grew and grew. This required the invention of Responsive Web Design which allows a web page to resize itself according to the dimensions of the device on which it is being run.
In 2017, at the request of my business partner, I made a modification to the RADICORE framework which turned my ERP application into the The World's First Mobile-First ERP by creating a plug-in which utilises the Bootstrap library. This is a plug-in which, when installed, can be turned ON or OFF for individual screens as well as individual users. It consists of a new directory, which is installed in the RADICORE root directory, called responsive-web which then contains three subdirectories called css, javascript and xsl.
Programmers who have already used the bootstrap library will know that it requires each HTML document to be modified to refer to a new set of CSS and Javascript files. At the time this application had over 2,700 screens, but I managed to convert all of them in under one man-month. "How was this possible?" I hear you ask. The answer is simple - my use of XSL stylesheets, specifically a library of 12 reusable XSL stylesheets, to build each web page. Every page is built from a series of templates, and each template is defined once and kept in a single place. All I had to do was make a series of amendments to those templates, a small amendment to the object which creates the XML document, and it was Job Done!
Note that this plug-in is only available to RADICORE users with a commercial licence.
As far as I am concerned a good design decision is one that has not had to be reversed or backed out, one that has always worked as intended and perhaps enabled the application to grow into areas which may have been completely unforeseen when it was originally taken. If a design causes the growth of your application to hit a brick wall, a cul-de-sac, then that is not good. You have to reverse out, undo what has been done, and try a new direction, a new path. Recovering from a bad design takes a lot of effort and can be a slow, expensive and painful process.
The following decisions have been in operation for over 20 years and have provided nothing but benefits:
I had used the monolithic single-tier architecture in COBOL for 16 years, but when I was exposed to working with a 2-Tier and then a 3-Tier Architecture (3TA) in UNIFACE I could immediately see its benefits, so I wanted to use this in my PHP framework. This was surprisingly easy as programming with objects is automatically 2-tier to begin with. This is because after creating a class for a component in the business/domain layer with properties and methods you must also have a separate component in the presentation layer which instantiates that class into an object so it can then call whatever methods are required. The object in the business/domain layer I now refer to as a Model and the object in the presentation layer I now refer to as a Controller.
I later discovered that 3TA is also an implementation of the Single Responsibility Principle (SRP) which is also the same as Separation of Concerns (SoC). This also demonstrates high cohesion which is supposed to be better than low cohesion.
Originally I did not put the code which generated SQL queries into a different object, I put them into separate methods instead called _dml_insertRecord(), _dml_getData() , _dml_updateRecord() and _dml_deleteRecord() in the abstract table class. These all used the original MySQL interface. A short while later when MySQL 4.1 was released it made use of a different "improved" interface, so I copied these methods to a separate dml.mysql.class file and changed the _dml_* methods to to call the corresponding method in this object. I then copied this to produce a new dml.mysqli.class so that I could change all the API calls. I then created a new method which instantiated the correct class according to which MySQL extension had been loaded. Easy Peasy Lemon Squeezy.
My decision to produce all HTML output using an XML file which could be transformed using an XSL stylesheet caused me put put all that code into a separate object which was called from the Controller after the Model had finished its processing. A colleague later pointed out to me that by splitting my presentation layer into two separate components I had in fact created an implementation of the Model-View-Controller (MVC) design pattern. Note that this was completely by accident and not design (pun intended).
I knew when I started this framework that I would be creating large numbers of HTML documents, and I did not fancy the prospect of creating each one individually. I had encountered the XSL templating engine during my days days working with UNIFACE and experimented with it on my home PC, so I thought that it could be useful.
I started by building a separate XSL stylesheet for each web page. Then I discovered how to build parts of pages using templates which could be loaded from a central library, and this greatly reduced the amount of duplicate code that I had been writing. This then led to the following enhancements to my framework:
The advantage of this approach is that nothing is written to the output stream until all other processing has been completed, which means that building the XML document and performing the XSL transformation is always the final act of every script. At any time before this happens I am able to use the header() function to jump to another script without hitting that "Headers already sent" message. This also means that it does not matter in what order I add the data to the XML document as the XSL stylesheet can extract the data in whatever order is necessary to build the HTML output.
It was standard practice in my COBOL days to design the database before writing any code. This was emphasised in a course on Jackson Structured Programming which showed the benefits of using a structure in the software which mirrored the structure of the database. Having worked with programs which did not follow this advice I can personally vouch for its effectiveness.
With UNIFACE it was impossible to write components which did not mirror the database structure as that structure had to be defined in the Application Model before any components could be built. Each component was built around an "entity" in the Application Model which represented a table in the application database.
I continued with this practice of designing the database first when developing my PHP framework for the simple reason that it had already been proved to me that it produced better results than any alternative approach.
The idea of building a mock database object to test my code before I build a real database table has always struck me as being a ridiculous practice. It was never suggested in my COBOL days and was physically impossible with UNIFACE. I have absolutely no problem with building my database first as then I can bypass all this mock object nonsense and start testing my code against a real database. It is no big deal if I have to change a table's structure later on as a copy of that structure is maintained within each table class courtesy of a table structure file which can easily be regenerated to deal with any changes.
Before you can start programming with objects you must first create classes from which objects can be instantiated. This utilising the first principle of OOP which is Encapsulation. This involves identifying an entity which will be of interest to you application, something with data and operations which can be performed on that data, then creating a class file with methods that correspond to the operations and properties which correspond to the data.
In the RADICORE framework each class for entities in the business layer follows the same conventions:
The idea of creating a separate class for each database table is actually recommended in the principle of Information Expert (GRASP) which states the following:
Assign responsibility to the class that has the information needed to fulfill it.
I interpret "responsibility" to mean code and "information" to mean data, so because each database table is responsible for a different set of data it follows that I should have a separate class to control access to that data, and that class should also contain all the methods which can act upon that data.
Because every table class follows the same conventions, the same pattern, using information which already exists the the database's INFORMATION_SCHEMA, this made it possible for me to automate the generation of all table class files.
I have been told on more than one occasion that having a separate class for each table is not proper OO, that real OO programmers don't do it that way, but I consider that their arguments are not worthy of consideration.
I have seen other programmers suggest using method names such as insertCustomer(), insertProduct() and insertOrder(), but they fail to realise that using method names which are tied to a particular object immediately rules out any chance of reusability using polymorphism, and as far as I am concerned any practice which eliminates the possibility of creating reusable code is a bad practice which should be avoided. Any practice which increases the possibility of creating reusable code is a good practice which should be encouraged.
It was obvious to me from my decades of experience prior to switching to PHP that the only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD), so I built corresponding methods into my abstract table class. Decades later when I read Designing Reusable Classes which was published in 1988 by Ralph E. Johnson & Brian Foote I realised that what I had done had already been identified as a Good Thing ™.
Each of my Controllers can then use the exactly the same methods on any Model, which meant that I had utilised the third principle of OOP which is Polymorphism. Note that polymorphism allows you to call a method on an object where the identity of that object can be switched at run time in order to provide a different implementation using the technique known as Dependency Injection.
Note that each of the common table methods has several steps which are always executed in the same sequence. A competent programmer should immediately identify this as a crucial step in being able to implement the Template Method Pattern. When I realised later that I needed a way to insert custom logic into certain table classes at certain points in the processing sequence I found that I could amend my abstract class to include "hook" methods which could be overridden in any concrete class.
All the sample code which I read in books or internet tutorials used a separate class property for each table column, which then meant having code to to insert or extract that data one column at a time. However, when I experimented with PHP I realised that data being sent to a PHP script from a web page is presented in the form of an associative array, and data being retrieved from a database row is presented in the form of an associative array, so I wondered why some programmers seem to think that it is necessary to split the array into its component parts during its journey through the business layer. I did an experiment and left the array intact, which meant that I could pass the array from one method to another in a single $fieldarray argument. As far as PHP is concerned when accessing a column's value there is absolutely no difference between $fieldarray['column'] and $this->column.
By using this approach I am demonstrating loose coupling which is supposed to be better than tight coupling. This enables me to pass any amount of data from one object to other without having to deal with individual columns names. I can change the contents of the array at any time to include more columns, less columns and different columns, and I do not have to change any method signatures or the places where those methods are called. This is why each of my pre-written Controllers can communicate with any Model without being concerned with either the name of the Model or what data is being passed around. Because of this I have huge amounts of polymorphism which then enables me to utilise Dependency Injection within every user transaction.
This also allows me to have a single View component for HTML output as it can extract all the data from a Model using a single call to the getFieldarray() method. It is then a very simple procedure to iterate through the associative array and copy each element into an XML document.
For more of my thoughts on this topic please read Getters and Setters are EVIL.
The description of the 3-Tier Architecture clearly states that all business rules should be handled in the Business layer and not in either the Presentation layer or the Data Access layer. As shown in Figure 9 I have merged the 3-Tier Architecture with the MVC design pattern, which means that all of my business logic, which includes data validation and task-specific behaviour, resides in my Model classes. This is a logical arrangement as part of the data validation process is to ensure that the data destined to be stored in a database table matches the specifications of that table. This means that the Model must know what columns exist in that table as well as the datatypes for each of those columns. This is what I call primary validation while anything else is called secondary validation.
While all those junior programmers out there are still writing their own code to perform primary validation I have managed to avoid this boring and repetitive task by creating a standard validation object which is built into the framework and performed automatically. This is made possible due to the existence of the following in each Model:
By confining all business logic to the Model classes in the Business layer I can absolutely guarantee that there is no business logic in any of my Controllers, Views, and Data Access Objects. This then means that I can use those objects with any Model in the application as none of them are tied to a particular Model.
I still read articles and blog posts where some junior programmers (or "clueless newbies" as I like to call them) still think it is good practice to have all validation performed outside of the Model, such as in the Controller. By doing so they are preventing their Controllers from being reused with other Models, and anything which cuts down on the amount of reuse should not be regarded as "good practice".
Some inexperienced programmers think that it is good practice to handle all business rules in the Controller and leave the Model to do nothing but handle the data, but this leads to an anti-pattern known as the Anemic Domain Model which is considered to be a Bad Thing ™.
Some programmers think that it is a good idea to create a separate DAO for each database table, which means that they have not yet learned how to create a single DAO which can handle any number of database tables.
Every SQL query is a string which is built to a standard formula regardless of what table names and column names are being used, and PHP's string handling functions make it easy to build any string that takes your fancy. Combine this with PHP's array functions and it is very easy to convert the contents of an array into a string. This is where my decision to use a single array property for all application data shows its value as it makes it easy to extract the name of each column and its associated value using code as simple as this:
foreach ($fieldarray as $fieldname => $fieldvalue) { echo "Name={$fieldname}, Value={$fieldvalue}"; } // foreach
It then becomes very easy to transfer the contents of $fieldarray into the following query strings:
INSERT INTO $tablename SET field1='value1', field2='value2', ...
UPDATE $tablename SET field1='value1', field2='value2', ... WHERE pkey='pkey_value'
DELETE FROM $tablename WHERE pkey='pkey_value'
SELECT queries are slightly more complicated as they involve a group of substrings each of which may be empty. The default query will be set to the following:
SELECT * FROM $tablename [WHERE $where_str]
A more complicated query will be constructed from the substrings as follows:
SELECT $select_str FROM $from_str $where_str $group_str $having_str $sort_str $limit_str
This then means that the methods which produce the above query strings can work with any table in the database, which means that I do not have to construct a separate DAO for each table. I have a separate DAO for each supported DBMS (currently MySQL, PostgreSQL, Oracle and SQL Server) for the simple reason that they each use different APIs to execute the query.
I also noticed that while every DBMS is supposed to follow the same SQL standard some of the more complicated queries have slight (and sometimes not so slight) variations in their syntax. While I do all my development using MySQL and its syntax, when I find it necessary to adjust a query due to changes in syntax I can now isolate those changes within the DAO for that DBMS. This means that I can switch the DBMS at any time by changing a single entry in my config.inc file and it is only the component in the Data Access layer which is aware of this change.
From my previous experience it was obvious to me that each user transaction starts off by following exactly the same pattern - it performs one or more CRUD operations on one or more database tables while utilising a particular screen structure. If you look at hundreds of different transactions you will initially see that they all perform different sets of operations on different tables and with different screen structures. While a novice programmer may stop there because of all those differences, an astute and observant programmer may be able to look deeper and see some similarities among all those differences:
I have highlighted the words structure, behaviour and content because they were the factors that led me to design my library of Transaction Patterns.
Each of these processing cycles may need to be interrupted in various places so that custom logic may be performed, which can be achieved by inserting customised business logic into the relevant "hook" methods.
When dealing with two tables which exist in a parent-child relationship, thus forming an Association, the method suggested in OO theory is to go through the parent object in order to access the child object. This was not the method which I used in all of my earlier programming languages where it was standard practice to access the two objects independently and separately. We would always start with a screen which had a single row from the parent table at the top and multiple rows from the child table underneath, as shown in Figure 3 above. The steps taken to deal with this combination was always the same:
Duplicating this functionality in PHP meant that I built a Controller (please refer to the LIST2 pattern) which communicated with two Models as separate entities. This means that finding the foreign key and communicating with the child entity is done within the Controller and not by any special code within the parent's Model class.
This means that I can create a complex hierarchy of tables which can be several levels deep, but I do not need any code in any of the classes to deal with that hierarchy. I certainly do not have a single transaction to deal with the entire hierarchy as I create a separate transaction for each pair of parent-child tables.
During the development of my main ERP application I encountered requirements which could not easily be satisfied with any on the existing Transaction Patterns, so what did I do? I created new patterns, such as:
When I built my first framework in COBOL the initial version the components for both the framework and the application were merged together - the program code was merged into the same executable, and all the forms were compiled into the same forms file. This eventually proved to be problematic, so I eventually found a way to keep the files separate by utilising a MENUSON program and an Extra Data Segment (XDS) to move data between the two programs.
In order to achieve the same result in PHP I did not have to jump through so many hoops. Every PHP programmer knows that a web application does not require all of its components to be merged into a single program file as each URL can point to a different script on the server, and that script need only load those components which are necessary to complete a single task. The HTML documents that it uses do not need to be compiled and held in a central document store. The end result is that the application does not need to be held in a small number of large files, it can be held in a large number of small files which can be spread across a number of directories and subdirectories.
While each web application has a root directory on the server which is the starting point for every URL, it is possible for a URL to point to any subdirectory, and a script being run in one directory is allowed to access files in other directories. I knew that after building the framework that I would also be building and running any number of applications using the framework, and that each of these applications could be integrated so that they would appear to be just a small part of a larger whole, or as I call them separate subsystems which form part of a larger system. I decided that I wanted to keep each subsystem's files separate from the others which is why every one has its own subsystem directory under the root directory. The framework itself actually consists of four subsystems - Menu, Audit, Workflow and Data Dictionary.
After deciding to keep each subsystem's files separate from the others by putting them into separate subdirectories under the <root> directory, I knew that I would be creating different types of file, so I created a separate collection of subdirectories which appear under each <root>/<subsystem> directory, as shown below with the directory name default:
This means that when you are looking for a particular type of file for a particular subsystem you know exactly where to look, and this directory will not be cluttered with files of different types or from other subsystems.
This feature came in very handy when installing my main ERP application on a client's server. The application has 20 subsystems, but each customer only pays for the subsystems which they wish to use. This also means that we only need to install those particular subsystems. Each subsystem comes with its own zip file so that it can be unzipped into its own directory. This directory also contains the files to create the subsystem's database, load the subsystem's tasks and menus into the MENU database, and also load the subsystem's details into the Data Dictionary database. This also means that a subsystem can also be easily uninstalled if need be.
You should be able to see that these decisions have contributed to a framework which exhibits high cohesion and loose coupling, both of which are considered to be desirable traits.
It was not until several years after I had starting publishing what I had achieved that some so-called "experts" in the field of OOP informed me that everything I was doing was wrong, and because of that my work was totally useless. When they said "wrong" what they actually meant was "different from what they had been taught" which is not the same thing. What they had been taught, and which is still being taught today, is that in order to be a "proper" OO programmer you must follow the following sets of rules:
I have produced criticisms of some of these principle in the following:
The fact that they were taught one way to do things does not mean that it was the ONLY way, the one TRUE way, and that any other way is automatically wrong. When I examined some of these principles and practices and looked at the impact they would have on my code if I adopted them I was appalled. All I could see was where simplicity was being traded for unnecessary complexity and where the possibility of creating huge amounts of reusable code was being bypassed completely. I am a pragmatist, not a dogmatist, so I choose to follow only those rules, such as achieving high cohesion and loose coupling, which produce the best results, and I certainly will *NOT* follow any rules, principles or guidelines which drastically reduce the amount of reusable code that I currently have available in my framework as that would go against the whole idea of OOP which is supposed to increase not decrease the amount of reusable code.
When I read programming principles I expect them to be teaching aids, I expect them to be written by people who know what they are talking about in language which is simple enough for a novice to understand. Instead most of these principles appear to have been written by people with PhDs which can only be understood by other people with PhDs. They appear to have been written by a bunch of academics who are high on theory but low on practical experience, therefore as training material for the uninitiated they are a complete failure. Some of these principles are so badly phrased that I cannot understand what they are talking about. This can lead to different people coming up with different interpretations and mis-interpretations which then lead to faulty and sometimes useless implementations.
Most of these principles were written in the 1980s and based on their experiences with tiny applications written in the Smalltalk language which is compiled and strictly typed whereas PHP is interpreted and dynamically typed. Also, practices devised for writing programs which deal with bit-mapped displays which respond to mouse events are out of place with modern web applications which use HTML documents and only respond to GET and POST requests. I cannot see any evidence of any one of the authors having been involved in the development of large commercial applications which contain thousands of screens and hundreds of database tables, therefore, as far as I am concerned, they are not qualified to give "advice" on the writing of such applications.
Out of all the papers I have read the only one with logical explanations and sound advice which is still appropriate more than three decades later is Designing Reusable Classes which was published in 1988 by Ralph E. Johnson & Brian Foote. I have expanded on the points raised in my own article The meaning of "abstraction" I find it strange that even though I did not come across this paper until over a decade after I had completed my framework and released it as open source that my mind instinctively went down the same path as theirs and used the idea of programming-by-difference where I first create a collection of objects, then examine them to separate out the similar from the different, and then find a way to put the similar into sharable modules and to isolate the differences. Their description of how to use abstract classes properly should have been followed by the cowboys who came later and said inheritance is bad, use object composition instead
.
There now follows a list of the rules, principles and guidelines which I refuse to follow as instead of promoting the idea of creating reusable classes I consider them to be nothing but obstacles.
Just because you can model the real world does not mean that you should. It is only necessary to produce software models of those entities which are of interest to your application, entities with which your software will communicate. When writing a business application which deals with entities such as CUSTOMER and PRODUCT you will not be communicating with or controlling those entities in the real world, you will only be communicating with representations of those entities in a database, and those entities are called tables. You can ignore the operations which those real world entities can perform or have performed upon them as the only operations which can be performed on a database table are Create, Read, Update and Delete (CRUD). You can also ignore all those properties which are of no use to the application.
While other people are taught to design their software first using some peculiar (to me, at least) rules and regulations, and then try to squeeze in a database afterwards, I have always had great success by doing the exact opposite. I know from years of experience that the most important part of a database application is the database design, after which you can then structure your software around that design. Get the database structure right first, then write the software to follow that structure. If your database design is wrong then it will make it more difficult to write the software, or, as Eric S. Raymond put it in his book "The Cathedral and the Bazaar":
Smart data structures and dumb code works a lot better than the other way around.
It is interesting to note that the Wikipedia article on Object Oriented Design contains the following statement:
A data model is an abstract model that describes how data is represented and used. If an object database is not used, the relational data model should usually be created before the design since the strategy chosen for object-relational mapping is an output of the OO design process
The idea that you can design software which uses a database without first designing that database is without merit. As far as I am concerned when it comes to writing software which communicates with a database there are two conflicting theories - OO theory and Database theory - and I'm afraid that simply being taught a bunch of abstract theories without learning how to apply them in real life will invariably lead to a mucking fess (if you catch my drift). This reminds of an old saying:
Q: What is the difference between theory and practice?
A: In theory there is no difference, but in practice there is.
I would hazard a guess and say that my approach to writing database applications using OOP has been more successful than others simply because of the following:
Since a major motivation for object-oriented programming is software reuse then I concentrated my efforts by attempting to produce as much reusable code as possible. Where a supposed "best practice" failed to meet this target I ditched it in favour of a better one, one that produced better results.
Using one set of rules to design the database (refer to The Relational Data Model, Normalisation and effective Database Design for details) and a different set of rules to design the software will invariably produce a situation known as Object-Relational impedance mismatch for which the usual solution is to create a piece of software known as an Object-Relational Mapper (ORM). This handles the conversion of data structures whenever there is communication between the software and the database. Creating a problem and masking over the symptoms is, to me, entirely the wrong approach. As far as I am concerned the rules of Data Normalisation are far superior to and take precedence over any artificial rules which were dreamt up by some OO fan boys who have never designed a database and the software which uses that database. Up until the time I switched to using PHP I had designed the databases for numerous applications and had personally built hundreds of user transactions. I had been exposed to multiple different ideas of how the code should be written, but I had learned to separate the wheat from the chaff and to only employ those practices which produced the best results. This can also be expressed as "the fewest problems".
I much prefer the idea that Prevention is better than Cure, so I take steps to ensure that my software is always synchronised with the structure of my database, thus totally avoiding the need for any sort of mapper. I do this by creating a separate class for each database table and ensuring that the common table properties are kept up to date with the physical structure of that database table. As well as being able to generate classes for new database tables at the touch of a few buttons I can also change the structure of a table and have those changes transmitted to the table's class at the touch of a few buttons. I have been using this approach for over 20 years with hundreds of database tables and it has performed flawlessly.
Among the peculiar complaints I have received from my critics are:
For more of my thoughts on this topic please read Object-Relational Mappers are EVIL!
I have seen finder methods used in various implementations of the ActiveRecord pattern where there is a separate method to supply specific selection criteria which can be used in a SELECT query. Having dealt with SQL queries for many years before switching to PHP I find this practice to be very peculiar. If you look at the structure of a SELECT query in SQL you should see that it is a string of plain text which consists of a series of substrings, each with a particular purpose. All selection criteria goes into the WHERE string except when it involves evaluating an expression in which case it goes into the HAVING string.
The format of the SQL query does not change because of what is in the WHERE and HAVING strings, so I see no reason why I cannot cover all possible selection criteria with a standard getData($where) method.
For more of my thoughts on this topic please read A minimalist approach to OOP with PHP - Finder methods
The ability to write software with large numbers of reusable components is a direct result of being able to spot patterns of similarities. Having built a large application which contains hundreds of database tables and thousands of user transactions (tasks) I found it impossible not to spot the following similarities:
Any programmer who cannot spot those patterns has zero chance of being able to provide reusable software to deal with those patterns, and since a major motivation for object-oriented programming is software reuse, the inability to write reusable software should be regarded as a clear indication of that person's failure as an OO programmer.
In the paper Designing Reusable Classes the authors wrote the following:
A framework is a set of classes that embodies an abstract design for solutions to a family of related problems, and supports reuse at a larger granularity than classes.
One important characteristic of a framework is that the methods defined by the user to tailor the framework will often be called from within the framework itself, rather than from the user's application code. The framework often plays the role of the main program in coordinating and sequencing application activity. This inversion of control gives frameworks the power to serve as extensible skeletons. The methods supplied by the user tailor the generic algorithms defined in the framework for a particular application.
RADICORE fits this description of a framework due to the following:
I do not need to spend any time in designing components for each user transaction as each of those components must conform to a pre-defined pattern, and I can build components from that pattern. In the case of Controllers, Views and Data Access Objects these are actually pre-written and supplied by the framework while Model (table) classes inherit all their common properties and methods from an abstract table class which is also supplied by the framework. I don't have to waste time with any other design methodology as this will produce components which cannot function within my framework.
In most of what I read on OOP uses the words "type" and "class" as if they mean the same thing. This causes the vast majority of inexperienced programmers, when creating a class for each database table, to regard each class as a separate "type". This is wrong. Each "type" must be totally different from all other "types", otherwise they could become "subtypes" of a supertype. After creating classes to handle the business rules for several tables an observant programmer should be able to spot certain similarities as well as differences within these classes. I spotted a bunch of similarities after creating just two table classes, and I found that the best way to share instead of duplicate the similarities was to move the common protocols to an abstract class which could then be inherited by each concrete class. Over a decade later, after reading Designing Reusable Classes, I discovered that this was the recommended way to deal with this situation.
As the major motivation for using OOP is the creation of more reusable software then the ability to spot patterns or similarities in the code is a prerequisite of putting that similar and repeating code into a central reusable module so that it can be referenced many times instead of being duplicated. This idea is expressed in the Don't Repeat Yourself (DRY) principle.
A programmer who cannot spot and deal with these patterns will never be much of a programmer, he will be more of a liability than an asset. Such a programmer is then likely to compound this error by mis-applying the "IS-A" test to create hierarchies of subtypes (see below).
In OO theory "IS-A" is a subsumptive relationship between abstractions (e.g., types, classes), wherein one class A is a subclass of another class B (and so B is a superclass of A). In other words, type A is a subtype of type B when A's specification implies B's specification. This is commonly used by developers who, when spotting expressions such as "a CAR is-a VEHICLE", "a BEAGLE is-a DOG" and "a CUSTOMER is-a PERSON", create separate classes for each of those (sub)types where the type to the left of "is-a" inherits from the (super)type on the right. This is shown in this wikipedia page on subtyping which shows an abstract class "Pet" with separate subtypes for "Cat" and "Dog".
This is not how such relationships are expressed in a database, so it is not how I deal with it in my software. I do not regard each table as a separate "type" when is is actually a concrete sub-type of an abstract super-type. I have an abstract table class which defines the characteristics which are common to every database table. This is then inherited by every concrete table class which provides the unique characteristics of a physical. database table.
Note that in my framework I never inherit from a concrete table class to create a different concrete class (by which I mean a class for a different table). I only ever create a subclass when I want to provide a different implementation in a "hook" method. This is because the number and names of these methods comes from a finite list, and sometimes there is a need for a different implementation in the same method. For example in the DICT subsystem I have the following class files:
Please refer to Using "IS-A" to identify class hierarchies for more of my thought on this topic.
In OO theory "HAS-A" is a composition relationship where one object (often called the constituted object, or part/constituent/member/child object) "belongs to" (is part or member of) another object (called the composite type or parent), and behaves according to the rules of ownership. The child object is then defined as a property of the parent and in some cases can only be accessed through that parent.
This is not how databases work, so it is not the way that my software works. Every table is treated as an independent object. If two tables are related then the only requirement is that the child table has a foreign key which points to the primary key of a record in the parent table. There is no need for anything else in each table class other that an entry in either the $parent_relations or $child_relations arrays as all other relevant processing is performed by the framework.
Please refer to Using "HAS-A" to identify composite objects for more details.
The idea that these two concepts are identical is the result of too many people using vague and inaccurate descriptions for each.
Far too many programmers are taught that encapsulation is the same as data hiding which forces them to use access modifiers to prevent unauthorised access to an object's data. This is not the case as encapsulation provides implementation hiding where a method signature is exposed while its internal implementation, the code behind that method, is not. This allows the implementation to be changed without having any effect on the code which calls that method. I have always thought that the idea of data hiding seems nonsensical - if the data is hidden then how are you supposed to put it in and get it out? Who are you supposed to be hiding it from, and why?
I do not use any visibility options on any data variables within my classes for these reasons:
Far too many programmers write code in which the functioning of an object requires separate methods for load(), validate() and store() where the load() usually requires separate setters for each column within that table. This opens up the possibility of allowing a column's data to be modified after the validate() method has been performed which could potentially lead to invalid data being sent to the database.
In my pre-OO days I learned that whenever a group of functions had to be executed in a particular sequence it was better to create a wrapper function to execute that sequence so that you only had to write a single call to the wrapper function instead of duplicating the same sequence of several function calls. This is why I created a single insertRecord() method as a wrapper for all those internal methods. It should be obvious that once this method has been called with an array of data it is physically impossible for an outside agent to change any value in that array after it has been validated and before it gets written to the database.
While learning PHP I discovered the $_GET and $_POST variables which made data sent to the client's browser available to the PHP script on the server. I also discovered that when reading data from the database the result was delivered as an indexed array of associative arrays. I was quite impressed with PHP arrays as they are far more flexible and powerful than what was available in any of my previous languages, so imagine my surprise when all the sample code which I saw had a separate class property for each column. I asked myself a simple question:
If the data coming into an object from the Presentation layer is given as an array, and the data coming in from the Data Access layer is given as an array, is there a good reason to split the array into its component parts for its passage through the Business layer?
With a little bit of experimentation I discovered that it was very easy within a class to deal with all that column data in an array, so I saw absolutely no advantage in having a separate property for each column. There is no effective difference between the following lines of code:
$this->column_name $fieldarray['column_name']
The only genuine reason for have separate properties for each piece of data is when that data arrives one piece at a time (such as with the multitude of separate sensors in an aircraft's flight control system) instead of in chunks (such as when posting an HTML form). If the data being loaded into an object from both the Presentation layer and the Data Access layer is in the form of an array there is no benefit in splitting that array into its component parts for its journey through the Business layer. Not only do I save code by not doing what is unnecessary I actually contribute to the desirable aim of loose coupling as all the object's data, no matter what data from what object, is passed around as a single $fieldarray argument. This means that I can change the contents of that array at any time without having to change any method signatures, thus avoiding the ripple effect which results from tight coupling, which is supposed to be a Bad Thing ™.
By not having a separate class property for each table column I also avoid the need for pairs of Setters and Getters.
As I don't have a separate class property for each table column I have no need for a pair of getters and setters to access that column's value. Add data goes in and comes out again in an array called $fieldarray.
More of my thoughts on this topic can be found in the following:
By this I mean the use of the keywords interface and implements, as explained in the PHP manual.
PHP4 did not contain support for interfaces, so I did not know that such things existed. I later read where some developers claimed that they were an "important" element in OOP, but after investigating them I concluded that they were actually "irrelevant" as they provided zero benefit from the effort involved in changing the code to use them. When I tried to find out where the idea of interfaces originated I was surprised to discover that they were created decades ago to deal with a problem in statically typed languages which could not provide polymorphism without inheritance. PHP is dynamically typed and does not have this problem, so the use of object interfaces in PHP is actually redundant.
Not only are interfaces redundant as their reason for being no longer exists, they have actually been superseded by abstract classes which provide genuine benefits:
More of my thoughts on this topic can be found at:
Shortly after I released my framework as open source I received the complaint from someone (refer to You should try object composition instead of inheritance) asking "Why are you using inheritance instead of object composition?" My first reaction was "What is object composition and why is it better than inheritance?" Eventually I found an article on the Composite Reuse Principle (CRP) but it did not explain the problem with inheritance, nor did it explain why composition was better. Those two facts alone made me conclude that the whole idea was not worth the toilet paper on which is was printed, so I ignored it.
I later discovered that problems with inheritance were caused by bad programming practices which could be avoided by only inheriting from an abstract class, which is precisely what I have always done. Please refer to the following for more details on this topic:
In OOP object associations are described thus:
Association defines a relationship between classes of objects that allows one object instance to cause another to perform an action on its behalf. This relationship is structural, because it specifies that objects of one kind are connected to objects of another and does not represent behaviour.
In generic terms, the causation is usually called "sending a message", "invoking a method" or "calling a member function" to the controlled object.
In a database these associations between two tables are called relationships and regardless of the type of relationship they are all defined in exactly the same way - the controlling object is known as the parent while the controlled object is known as the child, and the child table contains one or more foreign key columns which contain the primary key of an entry on the parent table. It is also possible for the child in one relationship to be the parent in another relationship. It is also possible for a table to have any number of parents as well as any number of children.
Objects in the real world, as well as in a database, may either be stand-alone, or they have associations with other objects which then form part of larger compound/composite objects. These compound objects are given different names depending on how they need to be treated.
While OO theory says that in any association the parent object should handle the method calls on each of its children I choose to do something different. Each table class contains nothing more than a $parent_relations and a $child_relations array which identify if a relationship exists while all method calls are made in a Controller such as one built from the LIST2 pattern.
More details can be found in Object Associations are EVIL.
One of the critics of my framework complained that it wasn't 100% object oriented
. When I asked for an explanation he said In the world of OOP everything is an object, so if you have something which is not an object then it's not 100% object oriented
. He pointed out that "proper" OO languages had support for value objects, so if I was using a language which did not support value objects then my work could never be 100% object oriented and therefore unacceptable to OO purists. I choose to ignore such an argument as the idea that everything is an object was never part of the original definition of what makes a language object oriented, it was one of those later additions by idiots who excel at taking a simple idea and making it more complicated than it need be.
The PHP language does not support value objects, the proof being that they are not mentioned anywhere in the manual. This has not stopped several developers from creating their own libraries of value objects, but I have no intention of using any of them. Even if they became part of the official PHP language I would still not use them. Why? Because they are an artificial construct which do not model anything which exists in the real world where every value is a scalar or a primitive. Converting such values into objects within the software would require a great deal of effort for absolutely no benefit for the simple reason that those value objects do not exist in the outside world.
As an example I shall take some blog post I came across recently which stated that currency values should be defined as value objects so that the value and its currency code could be kept together so that the currency code could not be accidentally changed without a corresponding change in the value. While this sounds like a good idea in theory it falls down flat in practice. Why? Because value objects do not exist in either the GUI or the database. In an HTML form you cannot insert a value object which has two values, you have a separate field for each value. You do not enter "125.00 USD" into a single field in the GUI, you enter "125.00" and "USD" into separate fields. You do not store "125.00 USD" in a single column in the database, you store "125.00" and "USD" in separate columns. The notion of converting these two separate values into an object while they exist in the the Business layer, then converting them back into separate values before they are passed to the Presentation and Data Access layers would be all cost and no benefit, so would automatically fail a cost-benefit analysis. I don't know about you, but in my world the result "zero benefit" equates to "not a snowball's chance in hell".
More of my thoughts on this topic can be found in Value objects are worthless.
When I began coding with PHP I followed the technique which I had seen in all the code samples I found and created a separate script for each web page, and then put the location of this script into my browser's address bar. When I was told by a colleague that I should be using the Front Controller pattern I asked "Why?" His response was: Because all the big boys use it, so if you want to become a big boy like them then you must use it too
. I thought his answer was total garbage, which is why he is now an ex-colleague. I asked myself the question "If running a web page in PHP is so easy then why would someone make it more complicated than it need be by inventing such a ridiculous procedure?" Then I remembered how COBOL programs worked. While a compiled program may contain a large number of subprograms in a single file it is not possible to execute a particular subprogram - you must RUN/EXECUTE the program file from the command line, which will always take you to address zero in the code, from where you can instruct it to CALL the relevant subprogram. This is done by passing an argument on the run command such as action=foobar, then having a piece of code called a router which calls the subroutine which is responsible for that action. It seemed that a lot of programmers who had started to use PHP had previously used a compiled language where a front controller was a necessity and assumed, quite wrongly, that it was the only way, the proper way, that it should be done. What idiots!
PHP is not a compiled language, therefore it does not need a front controller and a router. I can break down a large application into a huge number of separate scripts, and I can jump straight to that script by inserting its path into the URL of the browser's address bar. While inside one script I can jump to another by using the standard PHP header() function. This simple technique is supported by Rasmus Lerdorf who, in his article The no-framework PHP MVC framework said the following:
Just make sure you avoid the temptation of creating a single monolithic controller. A web application by its very nature is a series of small discrete requests. If you send all of your requests through a single controller on a single machine you have just defeated this very important architecture. Discreteness gives you scalability and modularity. You can break large problems up into a series of very small and modular solutions and you can deploy these across as many servers as you like.
I have written an application which contains over 4,000 user transactions (tasks) each of which can be selected by the user, but instead of going through a front controller each URL points directly to a separate script on the file system called a component script which looks like the following:
<?php $table_id = "person"; // identify the Model $screen = 'person.detail.screen.inc'; // identify the View require 'std.enquire1.inc'; // activate the Controller ?>
As you can see this accesses only those scripts which are are actually needed to carry out the designated task. It is short and to the point and goes directly to the right place - there is no beating about the bush or following multiple paths of indirection.
More of my thoughts on the subject of front controllers can be found Why don't you use a Front Controller?.
I was never trained to use Domain Driven Design (DDD) to design the objects in my Business/Domain layer which is precisely why I do not repeat the mistakes that it advocates. I started to read it to find out if I was missing something important, but I got as far as the statement "create a separate method for each use case" when the alarm bells starting ringing in my ears and a huge red flag started waving in front of my eyes. If I were to do such a foolish thing I would be closing the door to one of the most useful parts of OOP, that of polymorphism. As an example let's assume that I have objects called PRODUCT, CUSTOMER and ORDER and I want to create a new record for each of them. Under the rules of DDD I would have to do the following:
require 'classes/customer.class.inc'; $dbobject = new customer; $dbobject->insertCustomer(...); require 'classes/product.class.inc'; $dbobject = new product; $dbobject->insertProduct(...); require 'classes/order.class.inc'; $dbobject = new order; $dbobject->insertOrder(...);
You should notice that both the class name and the method name are hard-coded, which means that each of those 3 blocks of code would have to be in a separate controller. This would mean that the Controller would be tightly coupled to a particular Model, which is considered to be a Bad Thing ™. Instead I do the following:
$table_id = 'customer'; require "classes/$table_id.class.inc"; $dbobject = new $table_id; $dbobject->insertRecord($_POST); $table_id = 'product'; require "classes/$table_id.class.inc"; $dbobject = new $table_id; $dbobject->insertRecord($_POST); $table_id = 'order'; require "classes/$table_id.class.inc"; $dbobject = new $table_id; $dbobject->insertRecord($_POST);
In this arrangement it is only the first line in each block of four that would have to be hard-coded. In my framework the value for $table_id is defined in a separate component script. This script will then activate the same controller script which calls the insertRecord() method on whatever object it is given. If you look you should see that the last 3 lines of code in each of those blocks is identical, which means that you can define them in a single object which you can reuse as many times as you like. This is an example of loose coupling, which is supposed to be a good thing.
If you are familiar with the MVC design pattern you should know that the purpose of the Controller can be described as follows:
A controller is the means by which the user interacts with the application. A controller accepts input from the user and instructs the model and view to perform actions based on that input. In effect, the controller is responsible for mapping end-user action to application response.
As a simple example a user may request a task which implements the use case to "create a customer" while the controller translates this into "call the insertRecord() method on the customer object". By changing the hard-coded name of the object to a variable which is injected at runtime I now have a controller which can call the insertRecord() method on any object in my application.
If instead of using shared method names I used unique names I would be using the wrong level of coupling and removing any opportunities for polymorphism, which would mean no dependency injection, which would therefore mean less opportunity for having reusable objects like my controller scripts. OOP is supposed to increase reusability, so by using a method which decreases reusability seems like anti-OOP to me.
Some junior developers are taught that the six components in my family of forms constitute a single use case. That it what I was taught in my COBOL days. However, as I worked on more and more applications where the use cases got bigger, more complex and more numerous, I realised that the task of writing and maintaining the code was becoming more and more difficult. In order to make the programs simpler I had to make them smaller, and in order to do this I came to the conclusion that each member in that forms family should be treated as a separate use case in its own right and not part of a bigger use case. I knew that it would result in a larger number of programs, but I considered that it would be worth it in the long run - and so it came to pass. Some of my colleagues said that it would result in the same code being duplicated in many programs, but they obviously did not know how to create reusable modules.
Having a separate module as a controller for each of those use cases was indeed a step in the right direction. Not only do I have a separate Controller for each member of that forms family, each of those Controllers can be used with any Model in the application in order to perform the same set of operations on that Model. I do not have to have a separate version of a Controller for each Model as the Controllers have been specifically built to operate on any Model in the entire application.
Splitting a compound use case into individual tasks also made it much easier to implement Role Based Access Control as all the logic for checking a user's access to a task was moved out of the task itself and into the framework. As a task could only be activated by pressing its button, either on the menu bar or the navigation bar, it became easy to hide the buttons for those tasks to which the user did not have permission to access.
While each design pattern has a description somewhere it does not specify any particular implementation. However, there are plenty of examples from individuals, either in books or the internet, of how they have been implemented. Unfortunately some junior programmers, when they find an example which is implemented in their programming language, seem to take that example and treat it as the only way that pattern should be implemented. In all the examples I have seen of the MVC design pattern I have only ever seen a Controller which talks to a single Model. In those cases where the screen contains data from two tables in a parent-child relationship the Controller talks only to the Parent object, and talks to the child object by going through the parent object.
This is not how it was done in UNIFACE (see Figure 3 for an example), and it is not how I do it in my PHP framework. Where UNIFACE has separate entity frames for the parent and child tables and each frame issues its own SELECT query I have a separate zone for each entity and each zone is allocated its own table object in the Controller so that each object can be accessed directly and independent of the other, as shown in the LIST2 pattern. This is because I do not deal with associations in the way this is taught by OO "experts".
Note that when accessing two tables in the sequence child-to-parent I only use the child object because I can include a JOIN to the parent table in the SQL query which is generated for the child table. Note that it is possible for the framework to adjust SELECT queries to automatically insert JOINS to parent tables, as discussed in Using Parent Relations to construct sql JOINs.
In my early COBOL days I was taught to create programs which handled multiple forms/screens where each screen was part of a different user transaction (task), but later I decided to deal with each screen and its use case in its own separate subprogram. With UNIFACE it was impossible to do any different as each form component started with the definition of a single form/screen. I followed the same tradition in my PHP framework by creating Controllers which were tied to a single View, or possibly no View at all. If you examine my library of Transactions Patterns you will see that most are tied to a single HTML document, while some are tied to CSV output, some are tied to PDF output while a small number have no View at all.
Each table in the database has its own Model class in the Business/Domain layer, and I don't need to spend time working out what properties and methods should go in each class as every one follows exactly the same pattern:
I quickly realised when coding the class for my second database table that there was much in common with the code I had written for the first database table, and the idea of having the same code duplicated in every other table class I immediately recognised as being undesirable as it violates the DRY principle. Question: How do you solve this problem of code duplication in OOP? Answer: Inheritance. I built an abstract class which could then be inherited by every table class, and moved as much code as possible from each table class to the abstract class, such as the common table methods. This followed the procedure identified in Designing Reusable Classes which was published in 1988. At the end of this exercise I had removed every method out of each table class until there was nothing left but the constructor.
When it came to inserting custom code within each table class I followed the examples I had encountered in UNIFACE and a brief exploration into Visual Basic. In both of these languages you could insert into your object a function with a particular name and the contents of that function would automatically be executed at a certain point in the processing cycle. This told me that the runtimes for both those languages had code which looked for functions with those names, and either executed them or did nothing. How do you duplicate this functionality using OOP? Execute special methods which are defined in the abstract class but devoid of any code, then allow the developer to override each of those methods with different code in the subclass. Easy Peasy Lemon Squeezy. It wasn't until several years later that I discovered I had actually implemented the Template Method Pattern.
When I started working with PHP I did not follow any design patterns for the simple reason that I did not know that they existed. I kept hearing about them so I bought the GoF book just to see what all the fuss was about. I was not impressed. Instead of describing implementations that could be reused it simply described designs which you had to implement yourself. Most noticeable by its absence was my favourite pattern, the 3-Tier Architecture. Instead there was a collection of patterns which dealt with situations which I had never encountered in my experience of writing enterprise applications. It appeared to me that these patterns were written around using a compiled language which used a bit-mapped display for software other than enterprise applications with HTML at the front end and an SQL database at the back end. As I could not find anything of interest to me I put the book on a shelf where it lay, unread and gathering dust, for years.
While some people seemed to think that design patterns were the best thing since sliced bread I began to notice that others held an opposite opinion, as shown in Design Patterns - a personal perspective. The GoF book itself actually contains the following caveat:
Design patterns should not be applied indiscriminately. Often they achieve flexibility and variability by introducing additional levels of indirection, and that can complicate a design and/or cost you some performance. A design pattern should only be applied when the flexibility it affords is actually needed.
In the article How to use Design Patterns there is this quote from Erich Gamma:
Do not start immediately throwing patterns into a design, but use them as you go and understand more of the problem. Because of this I really like to use patterns after the fact, refactoring to patterns.
One comment I saw in a news group just after patterns started to become more popular was someone claiming that in a particular program they tried to use all 23 GoF patterns. They said they had failed, because they were only able to use 20. They hoped the client would call them again to come back again so maybe they could squeeze in the other 3.
Trying to use all the patterns is a bad thing, because you will end up with synthetic designs - speculative designs that have flexibility that no one needs. These days software is too complex. We can't afford to speculate what else it should do. We need to really focus on what it needs. That's why I like refactoring to patterns. People should learn that when they have a particular kind of problem or code smell, as people call it these days, they can go to their patterns toolbox to find a solution.
This sentiment is echoed in the article Design Patterns: Mogwai or Gremlins? by Dustin Marx:
The best use of design patterns occurs when a developer applies them naturally based on experience when need is observed rather than forcing their use.
I do not read about design patterns and try to implement them, I write code that works, and if a pattern emerges then great. If not, then who cares? I certainly don't. The only patterns which have any value for me, patterns which which exist in pre-written and reusable code, are Transaction Patterns.
Most junior programmers (or "clueless newbies" as I like to call them) are incapable of recognising a pattern on their own unless it has been described in a pattern book. These people will never be anything more than Cargo Cult Programmers as the ability to write reusable code requires the ability to spot patterns in either behaviour or structure, then to write code to implement those patterns which can be reused instead of duplicated.
It should be noted that exceptions were not invented for use in OO languages, they were invented to solve the Semipredicate problem which existed in earlier languages.
Exceptions did not exist in PHP4, so I could not use them in my code. This didn't bother me as I never even knew that they existed. I had already learned from my two decades of previous experience that when writing programs which allow users to enter data there are only two types of error:
The former are data validation errors, so it is perfectly acceptable to tell the user this value is wrong, please re-enter and try again
. The latter cannot be corrected by the user. They usually point to an error in the code which can only be corrected by a programmer, so the standard procedure is to write as much information to an error log and then terminate processing.
Treating recoverable errors as exceptions can have its drawbacks. I read a blog post years ago from a programmer who worked on a large java application where every exception was written to an error log, and it was his job every day to search through the log looking for errors that required fixing by a programmer. This was very tedious as 99% of the errors were validation errors and could not be fixed by a programmer.
As soon as exceptions were added to PHP5 far too many programmers jumped on the bandwagon and changed all their errors to exceptions. I could not be bothered as I already had a working solution, so I could not see the point in expending all that effort for zero benefit. I also saw a problem if I changed all my data validation errors to exceptions - by throwing an exception you automatically leave the current function, and this means that you can only report one error at a time. This is not user-friendly. If an input screen has ten fields all of which have invalid values the user wants all ten errors to be shown at the same time. That is why I continue to load all my recoverable errors into the object's $errors array. For irrecoverable errors I continue to use the trigger_error() function in conjunction with my own error handler.
More of my thoughts on this topic can be found in A minimalist approach to Object Oriented Programming with PHP.
The first time I encountered a team of developers who insisted of drawing UML diagrams for each and every use case the more exasperated I became as it took longer for them to draw the diagrams than it took me to write the code which implemented those diagrams. These diagrams became more complicated than they needed to be and contained a lot of duplication, so as an avid follower of the KISS and DRY principles I wanted something simpler and better.
If I build user transactions from a series of patterns where each pattern has a fixed and reusable implementation I do not see why I should duplicate the documentation for the pattern in every transaction that uses the pattern, so I made two decisions:
As each user transaction also follows the pattern of performing one or more CRUD operations on one or more tables I have produced UML diagrams for each of these operations - refer to ADD1, ENQUIRE1, UPDATE1 and DELETE1.
For the more complex Transaction Patterns each description contains a list of object calls which identifies which methods are called in which sequence. While all these methods are defined in the abstract class, some of them (those with the "_cm_" prefix) may be overridden in a concrete table class to provide customised business logic.
My reasons are as follows:
According to this wikipedia article the term GRASP stands for:
General Responsibility Assignment Software Patterns (or Principles), abbreviated GRASP, is a set of "nine fundamental principles in object design and responsibility assignment"
Most entries in the following list are not "requirements" at all, they are just principles which are only relevant in certain circumstances.
identify an entity/object which is of interest to your application, something which has data and operations which can be performed on that data, then create a capsule (called a class) to contain properties for the data and methods for the operations. Creating classes which contain data but no operations produces an anti-pattern known as an Anemic Domain Model, which should be avoided. The class should contain all the business rules for that entity and therefore be the "expert" for that entity. The idea that encapsulation means information hiding is also wrong - it should be implementation hiding as you still need to access the data.
Note that coupling is also affected by the number of connections as well as the complexity of each connection, so fewer and simpler connections are better. By replacing one direct call (from A to b) with two indirect calls (from A to C, then from C to B) you are doubling the number of connections and making the code less easier to understand.
Since a major motivation for object-oriented programming is the creation of more reusable software (ie: implementations which can be shared), I do not consider the use of object interfaces to be similar to or a substitute for inheritance as they do not contain implementations which can be shared.
While some naive programmers encounter problems with inheritance which cause them to favour object composition instead, I learned to do the right thing and only ever inherit from an abstract class.
Depending on what interpretation you put on the wording of this principle, it is possible that my framework already contains a proper implementation for the simple reason that all my Controllers and Views communicate, via polymorphism, with Models using interfaces (method signatures with implementations) inherited from an abstract class which have remained unchanged for 20 years. I have gradually increased my number of Controllers from 6 to 40, and I have increased my number of Models from 2 to 450, and I have added new methods to my abstract class, with corresponding calls in some Controllers, but the code which I initially created 20 years ago is still visible and viable. Does that count?
a class that does not represent a concept in the problem domain. This kind of class is called a service. This description is, for me, far to vague as it does not properly identify the difference between an entity and a service. I have found better descriptions which I have documented in Object Classification.
Productivity is defined as:
a ratio between the output volume and the volume of inputs. In other words, it measures how efficiently production inputs, such as labour and capital, are being used in an economy to produce a given level of output.
In the world of software development the usual measurements are time and money, i.e. how long will it take to complete and how much will it cost? After having worked for several decades in software houses where we competed for development contracts against rival companies the client would always look more favourably on the one which came up with the cheapest or quickest solution, with the reputation of the software company coming a close second. As the biggest factor in software development is the cost of all those programmers, it is essential to get those programmers producing effective software in the shortest possible time and therefore the lowest cost. The way to cut down on developer time is to reuse as much code as possible so that there is less code to write, less code to test, and less code to document.
Even early in my career I became quite proficient at creating libraries of reusable software, and when I upgraded this to build a fully-fledged framework on one particular project my boss was so impressed that he made it the company standard on all future projects. When the company switched languages from COBOL to UNIFACE I redeveloped that framework to take advantage of the new features offered by that language and reduced development times even more. When I decided to make the switch to the development of web applications using PHP I was convinced that I could reduce my development times even more. Although this was my first incursion into the world of OOP it seemed to be right decision as it promised so much:
The power of object-oriented systems lies in their promise of code reuse which will increase productivity, reduce costs and improve software quality.
...
OOP is easier to learn for those new to computer programming than previous approaches, and its approach is often simpler to develop and to maintain, lending itself to more direct analysis, coding, and understanding of complex situations and procedures than other programming methods.
As far as I am concerned any use of an OO language that cannot be shown to provide these benefits is a failure. Having been designing and building database applications for 40 years using a variety of different programming languages I feel well qualified to judge whether one language/paradigm is better that another. By "better" I mean the ability to produce cost-effective software with more features, shorter development times and lower costs. Having built hundreds of components in each language I could easily determine the average development times:
How did I achieve this significant improvement in productivity? Fortunately I did not go on any formal training courses, so I was not taught a collection of phony best practices. Instead I used my previous experience, intuition, common sense and my ability to read the PHP manual to work out for myself how to write the code to get the job done, then move as much code as possible into reusable modules. I already knew from previous experience that developing database applications involved two basic types of code:
This leads to two methods of developing your application:
The RADICORE framework makes use of the 2nd method. All standard functionality is provided by pre-built and reusable framework components while unique business rules can be added later in by using any of the pre-defined "hook" methods. In this way the application developer need spend minimum time dealing with the low-value background code and maximum time on the high-value business rules. In order to construct an application which can be run under the RADICORE framework all the developer has to do is the following:
If a table's structure ever changes all the developer has to do is to re-import and re-export that table's structure using the functions built into the Data Dictionary. There is no need for any of the following:
No code needs to be changed unless it involves an update to a screen structure script or some custom processing logic within the class file.
If you think that my claims of increased productivity are false and that you can do better with your framework and your methodologies then I suggest you prove it by taking this challenge. If you cannot achieve in 5 minutes what I can, then you need to go back to the drawing board and re-evaluate your entire methodology.
My collaboration with Agreeable Notion ceased in 2014 as they could not find enough clients. Their business model involved finding someone who wanted a new front-end eCommerce site and offering TRANSIX as the support application as the back-end. At about that time I had begun a conversation with a director of Geoprise Technologies who were a software company based in the USA but with offices in the far east. They had already used my open source framework to build one of their own applications, and when I mentioned that I had already built a entire ERP application they expressed an interest as they operated in the same business area. One of their directors flew into London so that I could give him a demonstration of what I had produced, and he was impressed enough to suggest that we form a partnership so that his company could sell the application using the brand name GM-X. This was quickly agreed, and in a short space of time we had our first client who was a large aerospace company.
Since that time I have made quite a few improvements to the framework as well as adding new subsystems to the ERP package. This is now a multi-module application where each client only needs to purchase a licence for those modules which they actually want to use. As it is a web application which runs on a web server, which could either be local or in the cloud, there is no fee per user, just a single fee per server regardless of the number of users. This multi-module application now consists of the following modules/subsystems:
This ERP package also has the following features as standard which are vital to software which is used by multi-national corporations:
Anyone who has ever developed a software package, which is akin to "off the shelf" rather than "bespoke", and therefore cheaper and faster to implement, will tell you that although it can be designed to provide standard functionality that should be common to many organisations, there will always be those organisations who have non-standard requirements that can only be satisfied with custom code. What I did not want to do was insert any of this custom code into the same place as the core package code, so I had to design a mechanism whereby I could keep the two types of code separate from each other, and to keep the customisations for one customer separate from the code for other customers. Some of these mechanism are described below:
This is where my use of a screen structure files for HTML screens and report structure files for PDF reports came in useful. Instead of looking in the standard screens and reports directories I created a new custom-processing subdirectory in each. In order to separate the customisations for one customer separate from those for other customers I decided to give each customer their own project code, and to use this code as a subdirectory in the custom-processing directory. I then updated the code which loaded these files to perform a lookup in the custom-processing/<project_code> subdirectory first, and if a file was foound it would load that one instead of the standard one. In this way simple cosmetic changes to screens and reports can be made relatively quickly and easily.
I solved the problem of providing customised business logic by extending my implementation of the Template Method Pattern which allows dummy methods in the abstract class to be replaced by customised "hook" methods in the concrete class. I created a separate custom-processing/<project_code> subdirectory in the classes directory into which I could store a file named "cp_<class>.class.inc" which would become the custom processing object for the current concrete class.
I then updated the code in the abstract class which calls the "hook" method to find out if a custom processing object had been defined, and if it had it would call the method in this external object instead of the method in the current object.
This feature was first documented in Blockchain for Blockheads.
In a Supply Chain Management (SCM) application there is often a need for communication between an organisation and its suppliers to deal with Requests, Quotations, Orders, Shipments and Invoices. These documents can be exchanged via email or web services, but these are not 100% secure and are open to attack by outside agents. However, now we are in the 21st century we can make use of a tamper-proof form of communication - a private blockchain. Some people think that a blockchain can only be used to deal with cryptocurrencies and is on an open network, but this is not the case. Any amount of data can be sent in a blockchain message, and the blockchain itself can be private so that only those who have been invited to join can use it.
Sending a message over the blockchain requires the following steps:
In order for data to be extracted from the application and sent over the blockchain network to other nodes on that network the application has to fire one of these blockchain triggers. These are identified on the BLOCKCHAIN_TRIGGER table. Each trigger identifies a set of circumstances - an insert/update/delete operation on a particular database table - which must be met in order for that trigger to be fired. For UPDATES this may require a change to a particular value in a particular column, such as the status of a purchase order being set to "Approved". This monitoring is performed automatically by the framework (in the abstract table class) as it knows both the name of the table and the operation which is being performed. No changes need to be made to any application component in order to configure any triggers. When the operation is successfully committed a new blockchain message will be constructed and sent out over the network (published).
Note that the execution of an online task cannot fire more than one trigger, so the following situations will result in excess triggers being ignored:
| Field | Type | Description |
|---|---|---|
| trigger_id | number | A unique identity number which is supplied by the system. |
| subsys_dir | string | The subsystem directory which contains table_id. |
| table_id | string | The name of the table. |
| table_id_alias | string | Optional. in some situations the table has an alias. For example, the ORDER_HEADER table has several variants:
|
| chain_id | string | Links to an entry on the BLOCKCHAIN_CHAIN> table. This identifies the chain to which the message will be sent. |
| stream_id | string | Links to an entry on the BLOCKCHAIN_STREAM table. This identifies the stream to which the message will be sent. |
| start_date | date | Identifies when this entry became active. |
| end_date | date | Optional. Identifies when this entry ceases to be active. Blank signifies an unspecified date in the future. |
| trigger_column | string | Optional. Identifies the column which contains the trigger_value. |
| trigger_value | string | Optional. Identifies the value in the trigger_column which will cause the trigger to be fired. |
| distribution_type | string | Identifies the recipients of the message. Options are:
|
| distribution_table | string | Optional. Identifies the table which contains one or more blockchain address to which the message should be sent. |
Note here that trigger_column and trigger_value must be either both empty or both non-empty.
When a trigger is fired the framework constructs a message by extracting the data for the current database row and copying it to an XML document. In some cases additional data has to be included from some related tables, so I created a separate RELATED_TABLE table to identify those related tables. For example, a Purchase Order will require data from the associated ORDER_ITEM table. Each related table, whether parent or child, can have related tables of its own, and whatever hierarchy is produced will be maintained in the XML document.
| Field | Type | Description |
|---|---|---|
| trigger_id | number | Links to an entry on the BLOCKCHAIN_TRIGGER table. |
| node_id | number | A unique identity number which is supplied by the system. |
| subsys_dir | string | The subsystem directory which contains table_id. |
| table_id | string | The name of the table. |
| table_id_alias | string | Optional. in some situations the table has an alias. For example, the ORDER_HEADER table has several variants:
|
| node_id_snr | number | Optional. Links to an entry on RELATED_TABLE table which indicates the senior (parent) table to this entry. An empty value indicates that the senior table is the root table, the one on the associated BLOCKCHAIN_TRIGGER table. |
| parent_or_child | string | Indicates if this table is the parent or child of the senior table. In a relational database two tables can be linked in a one-to-many relationship where the "one" is also known as the senior, parent or superior, and the "many" is also known as the junior, child, or subordinate. |
When a message is received the XML document identifies the operation which triggered it as well as the affected data table by table. It is a straightforward process to pick out each table's data, instantiate the object which deals with that table, then call the relevant method to perform that operation on that table with that data.
Further information on this topic is described in Adding Blockchain to an ERP System. Note that this enhancement was achieved in just one man-month with all coding confined to the framework and not any application components. Additional information can be found in Blockchain for Blockheads.
The structures of the core database tables are fixed for the simple reason that those structures are built into the core components which reference them, and changing the core components for any individual customers would be a logistical nightmare. However, it doesn't stop a potential customer from saying We would really like some extra fields on so-and-so screen
, so again I had to put my thinking cap on and devise a suitable solution. The first step in my solution was to add a new set of tables to the core database for each core table where these extra fields were required. These tables have the structure shown in Figure 11 below:
Figure 11 - Tables for User Defined Fields
")
Note that <TABLE> is the core table for which extra values are required.
| Column Name | Column Type | Description |
|---|---|---|
| Extra_id | String (40) | Identifies the field name for a user-defined value. This should NOT be the same as a field name in the associated core table. |
| Extra_name | String (80) | A user-friendly name for this field. |
| Extra_desc | String (255) | A longer description for this field. |
| Extra_type | String (255) | Identifies the data type for all values for this field. Options are:
|
| Is_required | Boolean | A Yes/No flag |
| Sort_seq | Number | Identifies the order in which the fields should appear on the screen. |
| Column Name | Column Type | Description |
|---|---|---|
| Extra_id | String (40) | Primary key of the associated EXTRA_NAMES table |
| Option_id | Number | A unique number assigned by the system. |
| Option_name | String | The name that will be displayed in the dropdown list |
| Sort_seq | Number | Identifies the order in which the fields should appear on the screen. |
The XXX_EXTRA_NAME_OPTIONS table identifies the options which should be displayed when extra_type is 'DROPDOWN'.
| Column Name | Column Type | Description |
|---|---|---|
| <primary_key> | Same as the primary key of the core table to which it is attached. | |
| Extra_id | String (40) | Primary key of the associated EXTRA_NAMES table |
| Extra_value | String (255) | User-defined value. |
The XXX_EXTRA_VALUES table holds the values for these named fields for different rows in the core table.
It is necessary to build a family of forms based on the LIST1 pattern for the XXX_EXTRA_NAMES table, and the LIST2 pattern for the XXX_EXTRA_NAME_OPTIONS and XXX_EXTRA_VALUES tables. As this meant that the values for the core columns and the extra columns could only be viewed on separate screens I decided to create a more advanced mechanism in order to merge the two sets of columns into a single screen. The screen in question is the DETAIL screen as used by the ADD, ENQUIRE, UPDATE and DELETE tasks. I achieved this by creating a trait which contains an extra set of methods. This trait contains the following methods which all have a "_udf_" prefix:
| Method | Description |
|---|---|
| _udf_getColumnSpecs | Read the XXX_EXTRA_NAMES table to obtain a list of additional columns with their specifications. If there are related entries on the XXX_EXTRA_NAME_OPTIONS table then load them into the $this->lookup_data array. |
| _udf_getColumnValues | Read the XXX_EXTRA_VALUES table for the current record and return an associative array containing all the values found. Any missing entry will be treated as NULL. |
| _udf_addFieldsToScreen | Add all the extra columns to the contents of the screen structure file which is held in memory. |
| _udf_updateFields | Update the XXX_EXTRA_VALUES table with the latest values from the current screen. If any value is empty the record will actually be deleted. |
| _udf_setSearch | Adjust the $sql_search string to look for records in the XXX_EXTRA_VALUES table instead of the current core table. |
| _udf_adjustQuery | Adjust the current SELECT query which is under construction to include all related values from the XXX_EXTRA_VALUES table. |
If the extra features required by the customer cannot be satisfied by any of the above, then there are two other options:
Each of the design decisions which I made when I started work on my PHP framework were not only good decisions on their own, but they had a knock-on effect which allowed me to create more and more reusable code and include more and more features. This fulfills the objective of using an Object Oriented language according to Ralph E. Johnson & Brian Foote who, in their paper Designing Reusable Classes, said the following:
Since a major motivation for object-oriented programming is software reuse, this paper describes how classes are developed so that they will be reusable.
Object-oriented programming is often touted as promoting software reuse [Fischer 1987]. Languages like Smalltalk are claimed to reduce not only development time but also the cost of maintenance, simplifying the creation of new systems and of new versions of old systems. This is true, but object-oriented programming is not a panacea. Program components must be designed for reusability. There is a set of design techniques that makes object-oriented software more reusable.
Data abstraction encourages modular systems that are easy to understand. Inheritance allows subclasses to share methods defined in superclasses, and permits programming-by-difference. Polymorphism makes it easier for a given component to work correctly in a wide range of new contexts. The combination of these features makes the design of object-oriented systems quite different from that of conventional systems.
They also explained the concept of programming-by-difference which I used extensively in my work, even though I did not read their paper until many years after my framework had been released as open source and after I had built my two ERP applications.
I have often been criticised by my fellow developers for not following their ideas on what constitutes "best practices", but in my humble opinion their definition as to what is "best" is subjective when it should really be objective. "Subjective" means that it is subject to someone's personal opinions, feelings and emotions while "objective" means it is based on verifiable information which is supported by facts and evidence, something which can be measured scientifically. Their philosophy is what I would call dogmatic as it is based on the following of rules with the assumption that they will always produce acceptable results. They follow principles and practices slavishly and indiscriminately without understanding either the problems which they are trying to solve or the solutions which they are trying to implement. In the end they become nothing more than Cargo Cult Programmers. My own philosophy, on the other hand, is pragmatic as it is based on achieving the best results using whatever practices seem to be the most appropriate for the current circumstances.
So how can you measure which approach produces the best results? If a major motivation for object-oriented programming is software reuse (as identified in the above statement from Johnson & Foote) then surely it can be measured by the amount of reusable code which you have produced which can then be compared with the amount of code which you have to write from scratch. If you look at the major components of each user transaction which my framework produces, which are shown in Figure 9, these contain the following amounts of reusable boilerplate code:
I am not aware of any other open-source framework which provides anywhere near the same levels of reusability.
That is a lot of code that you DON'T have to write. For further details please read Levels of reusability in the RADICORE framework.
What this means in practical terms is that after creating a table in my database I can use functions provided in the framework to build the class file for that table, then create a family of forms to view and modify the contents of that table simply by pressing buttons and without writing any code - no PHP code, no HTML code and no SQL code, and all in five minutes. If you do not believe me then watch this video. If you think that your favourite framework can do better then I dare you to take this challenge.
Here endeth the lesson. Don't applaud, just throw money.
The following articles describe aspects of my framework:
The following articles express my heretical views on the topic of OOP:
These are reasons why I consider some ideas on how to do OOP "properly" to be complete rubbish:
Here are my views on changes to the PHP language and Backwards Compatibility:
The following are responses to criticisms of my methods:
Here are some miscellaneous articles:
| 25 Jan 2025 | Added Designing forms using FORMSPEC
Added Accessing forms using VPLUS intrinsics Added Accessing the database using TurboIMAGE intrinsics |
| 03 Jan 2025 | Added Changing Programming Paradigms |
| 10 Aug 2024 | Added User Defined Fields (UDF)
Added Bespoke subsystems |
| 15 May 2024 | Added COBOL was strictly typed
Added UNIFACE was strictly typed |
| 17 Mar 2024 | Restructured document to include more sections with headings and hyperlinks for each. |
| 04 Feb 2023 | Added Dealing with RISC
Added Dealing with the Y2K enhancement |
| 05 Jan 2023 | Added I do not use Design Patterns
Added I do not use a Front Controller Added I do not use an Object Relational Mapper Added I do not use Value Objects |
| 01 Nov 2022 | Added Design Decisions which I'm glad I made
Added Practices which I do not follow Added From personal project to open source Added My second ERP package Added Maintaining the unmaintainable |