Figure 1 - A family of forms
This document describes my progress through the world of data processing, and highlights what I consider to be the points of significance in my career.
When I joined the IT industry (or 'Data Processing' as it was known in those days) in 1971 there was no need for university degrees, nor even 'A' levels or 'O' levels. All that was required was a simple aptitude test to find out if you had a logical mind - if you passed that you were in! I started off as a trainee computer operator on a Univac 1108 mainframe which ran at the amazing speed of 1 million instructions per second (that's 1MHz in today's language). The CPU was the size of a wardrobe, not like today's postage stamp. There was no disk storage, so we had to make do with a room full of tapes (12 inch spools which held 2400 feet of 3/4 inch tape). The printers were the size of a pair of 4 drawer filing cabinets and we had to keep them fed with boxes of 132 column continuous stationery. They were the old fashioned 'impact' printers, not like the laser or inkjet of today, and the mechanical parts required daily maintenance. Changing printer ribbons was a long and messy job. We kept the processor busy by constantly feeding it with decks of punched cards or rolls of paper tape. The operator's console was not a screen, it was a teletype.
I started with Shell International Petroleum in 1971, moved to Wates Computer Services in 1972, and in 1973 I moved to Financial Data Services where I made the move into programming. We worked a shift system to keep the machine running 24 hours a day, 7 days a week. The overnight batch processing was such that we needed a program to print each night's schedule of jobs. We had a COBOL program that someone wrote several years earlier, but we wanted some changes made to it. We asked the software department to make the changes for us, but they refused saying that such a menial task was beneath them. There is an old saying that "If you want a job doing properly you'd best do it yourself", so that's exactly what I did. I had never been on any programming course but I knew what the program did and I had access to the source code. I spent endless night shifts pouring over program listings trying to work out how it did what it did, and how to modify it to make it do what I wanted. I was hampered by the fact that the program was monolithic, unstructured, and badly documented, but at that time I simply assumed that that was the way programs were written. After a lot of trial and error, and a little luck, I managed to make the enhancements. When I showed them to the operations manager he was so impressed with my initiative that he arranged for me to be transferred to the software department (No, it was NOT to get me out of his hair! Honest!)
My first task as a trainee programmer was to fix some bugs in a suite of log file analysis programs. My new manager was too mean to send me on a training course, but at least he gave me some manuals. These new programs were a complete revelation to me - they had a definite structure, had in-line documentation, and the use of PERFORM instead of GO TO made it easy to follow the flow of logic as it jumped from one section to another. I did not need to be told that structured programming was better, I could see the results for myself. Not only was a structured program easier for a newcomer to read and understand, it was also easier to write, test, debug and enhance.
Some of the tasks required that I learn Assembler, a 2nd generation language that was one step away from machine code. As usual I did not have the benefit of any training course, so I struggled by with the manual and a few sample programs. At least these programs had a formal structure which made them relatively easy to follow. Despite these obstacles I managed to complete two programs that were released into production.
Over the following years as I came across more programs written by different programmers I noticed a definite difference in style and technique. I hadn't realised that there were so many different ways of achieving an objective. Some were simple, others were complicated; some were neat, others were messy; some were effective, others were flawed. I made a mental note of what worked and what didn't, and continually added to my personal catalog of what I thought constituted 'good programming'. I didn't need to be told what was good and what wasn't, I could tell from my own experience whether something was a help or a hindrance in writing a better program. Other programmers seemed to be happy in doing things the same old way, but I was always on the lookout for a better, neater, more efficient way.
I eventually left that company and joined a major software house where I worked on several different projects. As a junior member of the development team I naturally followed the lead set by my superiors. I did what they told me to do in the expectation that I was learning the right way to do things. However, as I moved from one project to another I noticed that each team had a different set of standards. Some things that were encouraged in one project were discouraged in another. Instead of "Do this, don't do that" it was a case of "Do that, don't do this". I began to question some of these statements, but the answers I received were anything but satisfactory:
On one particular project I was required to write a program that included several complex calculations, and those of you who know COBOL will recognise the usefulness of the COMPUTE verb. However, the project standards stated quite categorically "Do not use the COMPUTE verb". I asked the project leader why and was fobbed off with the reply "Because it is inefficient!" I was not happy with this answer as I had used this verb successfully in other programs on other projects, so I asked for a fuller explanation. Eventually this was the answer I received:
Programmers who learned BASIC use the statementA=A+1to increment a value, and when doing the same thing in COBOL would translate it intoCOMPUTE A=A+1. This use of the COMPUTE verb is not efficient - the statementADD 1 TO Ashould be used instead.
When I asked why the standards contained a blanket ban instead of a balanced explanation I was told quite brusquely "Because I shouldn't need to give explanations for each and every rule!". I began to question some of the other statements in the project standards and quickly realised that a lot of them were based on unsubstantiated or second hand opinions. Instead of being examples of programming excellence they merely reflected the limited experience of the author. Some of the rules appeared to have been the result of the toss of a coin rather than direct experience. There came a point with a particularly difficult program when I realised that I was being hampered by my attempts to adhere to the standards. Instead of helping me to write quality software these standards were proving to be nothing but a hindrance, so I eventually decided to abandon them and do my own thing. Several weeks later there was a project audit by a senior consultant and my program was one of those selected for a code review. I still vividly recall the words on his report:
In an audit against the project programming standards this program is not very good however, in the auditors opinion, this is one of the best written and documented programs of all those examined.
This raised some very important questions in my mind:
The moral of this story is that you should not prohibit anything unless you have a legitimate reason. All this particular "problem" actually required was to educate the developers in when it was OK to use the COMPUTE verb and when it was more efficient to use something else.
On a later project I came across a situation where the project standards had not kept up with developments in the language which could have reduced the amount of programming effort in a certain area as well as removing a cause of annoying bugs. With that language all the screen layouts were compiled in a separate form file, and each field in a form had a name as well as a number. The name had to be unique but was user definable whereas the number was allocated from an internal sequence. If a field was deleted its number was not reusable, and as field numbers could not be greater than 255 it was sometimes necessary to use a procedure to renumber all the fields in a form in order to make new numbers available for new fields.
When programmers wrote the code to validate user input and an error was found it was necessary to highlight the offending field and load a message into the message area, which was done by calling a system function called VSETERROR. The problem with this routine was that it required the field number, not its name, so the poor programmers had to devise a way of translating field names into numbers before calling this routine. Some created arrays which they used as lookup lists while others did it the old fashioned way by writing long-winded IF ... ELSE ... statements. This resulted in a great deal of effort in writing the code to translate field names into numbers as well as annoying the users when the numbers were wrong which caused the wrong field to be highlighted on their screens. Should a form require to be renumbered so that a new field could be added the maintenance overhead was a nightmare as all those programs which referenced that form (and forms were very often shared by several programs) would have to be modified accordingly.
What the project leader in charge of the development standards had failed to notice was that over a year earlier a new version of the software had included a routine called VGETFIELDINFO which, among other things, provided the ability to return a field number from a field name. I discovered the availability of this routine by reading the updated manual (in those days they were all printed) instead of the older versions which were still floating around. I asked the project leader why he wasn't encouraging the use of this new routine only to be told that the project standards were none of my business and besides, all the programmers were used to doing it the old way and would be confused if they had to work on programs which did it differently. He also said that it wasn't possible to change all the programs in one go as it would require an enormous amount of effort as well as holding up all current development work.
This did not deter me from making use of this new feature in the programs that I worked on. I cut out all the useless code and replaced all the calls to VSETERROR with a subroutine which also included VGETFIELDINFO. Gradually some of the other programmers became aware of what I was doing, and when they realised the benefits over the old way they began to use the same technique in the programs that they were working on.
The moral of this story is that you should always keep an eye open for newer and better ways of doing things. Reading the manual, especially after a new version of the software is released, can often be quite revealing. You should also not be afraid of introducing new techniques on a program-by-program basis rather than stopping to change the entire system in one fell swoop. Rather than confuse the programmers they may actually welcome the opportunity to replace problematic code with a simpler and error-free solution.
On another project I came across a situation in which the solution to a particular problem actually generated problems of its own. The original problem concerned the way in which programmers dealt with unexpected errors (such as network failures) they encountered at runtime. The common practice was simply to use a STOP RUN command to abort the program at that point, but this had unfortunate consequences:
The solution was to insist that every subprogram contained code so that if an irrecoverable error was encountered it set an error flag and then cascade all the way back to the controlling program. As this was where the files had been opened in the first place it was considered the best place to close them. An attempt was also made to include some sort of error report by printing out the contents of several communication areas.
This "solution" caused the following problems:
A superior solution which I designed and implemented when I was a project leader on a subsequent project was to build an error handler which could be invoked as soon as an error was encountered. Thus instead of the STOP RUN command which caused the original problem all the programmer had to code was "call TONY'S-ERROR-HANDLER". This solution had the following advantages:
The moral of this story is not to implement a solution which, while it may solve one problem, actually generates a set of new problems.
One particular project had a design decision regarding the use of programs and subprograms which both I and the users found questionable. For those of you who do not understand the difference between the two here is a brief comparison:
| Programs: | Subprograms: |
|---|---|
| Are invoked from the command line. | Can only be invoked from within another program. |
| Run in their own process. | Run within the process of their parent program. |
| Take time to start as the operating system has to create a new process before they can be loaded into memory and the code executed. | Are faster to invoke as it is not necessary to create a new process. |
| Cannot share resources with other programs. | Can share any resources within their own process. |
| Cannot easily communicate with another program (process). | Can easily communicate with another subprogram within the same process. |
The advantage of a system built from subprograms from the user's point of view is speed. Once the program has loaded and opened its files it is possible to switch from one subprogram to another very quickly, and to pass information such as current context from one subprogram to another. When forced to switch to another program the time delay (in those days) was relatively enormous - time was needed to create a new system process and time was needed to open all the application files. The mechanism used to pass current context between one program and another was not very elegant - it required the user to type it into a separate box so that it could be written to a file which could then be accessed by the new program.
I asked why it was not possible to invoke all the application subprograms from within a single program and thus remove all those delays that the users kept complaining about. I was told quite simply that the system architecture did not allow it, therefore it was impossible. This did not seem right to me as I had heard of other applications being built around a single program, so I knew it could be done.
The problem with the system architecture was the amount of memory that could be used by each process. Each COBOL program/subprogram was divided into a data area and a code area and neither could exceed 32K words (where a word was 2 bytes) otherwise it would not compile. Most subprograms used far less than this, and it was possible to combine several into the same program file provided that the total size of the code and data areas did not exceed the 32K limit.
The way that program files were constructed from groups of subprograms was quite involved. COBOL source was compiled into intermediate files called Relocatable Binary (RB) which were then grouped together with a Link Editor to form either an executable program/absolute (ABS) or a Relocatable Library (RL). The link editor enabled the developer to take the RB's from several subprograms and group them together into program segments. No individual segment was allowed to exceed 32K in either data or code, but it was possible to create any number of segments.
The grouping of subprograms into individual program segments needed careful thought. While it was possible for a subprogram to invoke another which existed in the same segment it was not possible to invoke a subprogram in another segment if the combined size of the two segments exceeded the 32K limit. Under these circumstances the only way to pass control from one segment to another was to exit the first segment and return to the control program (known as the Outer Block) which could then invoke a subprogram in another segment.
The problem here was that the users wanted to be able to jump from one subprogram to another without having to exit back to the control program, but this was only possible if the new subprogram could be loaded into memory without falling foul of the 32K limit. If this ever happened there was no polite warning - the program simply aborted. The designers of this system clearly did not want this to happen, so they built the entire system around multiple program files where each program could never exceed the 32K limit and therefore fail. This did, however, limit the user's ability to jump from one program file to another. They did not appreciate this limitation which was a cause of constant complaints.
A few years later I was Project Leader responsible for designing a brand new system (see My first complete Project) and leading a team of developers to build it. Amongst the problems I had to solve was - you've guessed it - the issue of allowing the user to jump from one subprogram to another with the minimum of delay and to pass current context automatically without it having to be re-entered. How did I solve it? As any competent programmer should - I analysed the problem then designed a solution.
The problem could be broken down into two conflicting requirements:-
The solution was to do it the way the system wanted it done, but to make it appear to the user that it was being done as he expected. I was aided by the fact that I had just designed and built a brand new dynamic menu and security system for the same project, and it turned out to be a relatively simple exercise to extend this design just a little bit further. The solution I produced went something like this:
The moral of this story is that not all problems are insurmountable barriers, they are merely opportunities for the developer to use his creative abilities to devise a solution. Large problems are merely collections of smaller problems, and by solving the small problems one at the time the large problem simply disappears.
As other people's standards appeared to be of extremely poor quality I decided to compile my own private standards. When I came across a different way of doing something I would examine it to discover if it offered any advantages over my current method. If it did I would adopt it, if it did not then I would ignore it. Sometimes the benefits would not be immediately obvious - several different items would need to be grouped together in order to produce a particular result. Sometimes a particular choice was discarded because it prevented something else from happening later on. For example, with the HP3000 VPLUS screen handler a screen could be constructed from several small forms or one big form. Although it was easier to use small forms this made it difficult to produce a screen print (a growing user requirement) as the in-built print facility would only work on the current form, not the whole screen. It was felt that the ability to produce screen prints was worth the additional effort in not using multi-form screens. This was actually a good move as it allowed me to implement a help subsystem later on - I could capture the current form name and its data content, replace it with a screen of help text, then reinstate the previous form and data when it was finished with.
Items were not included in my standards because of personal fancy - there was always a reason, whether it be efficiency, reliability, productivity, practicality, legibility, or maintainability. Unlike other people's standards mine included the reason for each decision so that I could always re-examine the logic at a later stage. Sometimes a change in circumstances such as a software update would cause me to re-evaluate a decision, but hey, that's progress.
The first time I exposed my standards to the scrutiny of others was when I was called upon to sort out the problems that a finance company was experiencing. Their whole development area was a mess - they shared the same area for both development and live software, they tested new programs on the live database, several versions of program source existed without any documentation which identified which was the current version, etc, etc. I would not have believed that a department could be so disorganised had I not seen it for myself. As well as teaching them how to write good quality programs I also had to teach them how to set up a proper development environment. When I left them everything was running smoothly and all the problems had disappeared, so I consider my efforts to have been successful.
The first time I got to use my standards on a complete project was for a custom Sales Order Processing and Sales Ledger System for a major publishing company in 1985. I helped prepare the design and development estimates that went into the proposal, and when the contract was awarded I was named Project Leader. I carried out the detailed design, produced program specifications, and was put in charge of the entire development team. As 'the man in charge' I set the standards and made sure everyone followed them. It wasn't a case of 'do it my way because I tell you to' but 'this way is better because...'. When people can see that your argument is based on common sense and logic and produces better results they are more likely to accept it and work with it.
This was also the project were I designed my first menu and security system. Up until that point all the menu screens that I had come across had been hard coded and therefore static. Just as we had started development the client suddenly decided that he wanted a more dynamic and flexible menu system, so I had to design and build one in a hurry. My design allowed for any number of menu pages to be defined or modified simply by changing data on the database rather than by changing program code and recompiling. There was only one menu screen in the system, and this empty screen was filled from the database at run time. Each time a new menu page was selected the screen would be cleared and loaded with a new set of details. A list of selections made in the current session was maintained so that the identity of the previous menu was always known and therefore could easily be reconstructed. By building security features into the menu system it was possible to edit the display of each menu page so that any options to which a particular user did not have access were not displayed. If the user could not see an option he could not select it. This meant that no security checking was required in any individual program as it was all performed within the menu system before the program was run.
This was the last major project that was developed on the client's own site. Subsequent projects were done in-house using our own facilities. It was then that our manager decided that we should have some official company standards which we could show customers if they asked to see them. He was willing to accept any rubbish that came along just as long as he could have a document with 'Company Development Standards' as its title. In his words "We've got to have standards, so any standards will do!" I remember having a heated discussion with him on the difference between intelligent standards and stupid standards, but he could not see any difference.
I proposed my own standards to the company, and as there were no other offerings mine were accepted by default. I asked the other programmers why they did not have any counter proposals and their response quite surprised me, but even today I notice that the same situation exists:
That is how I became the author of the company standards. The task was not forced upon me - I took it on quite willingly. Unlike all the other programmers in the company I considered that a sensible set of standards could have considerable benefit and had actually taken the time to create some. Nobody else could be bothered.
As well as COBOL Programming Standards and Project Development Standards I created the beginnings of a complete development environment by including a redesigned version of the menu and security system. I took out some of the features that the previous client had insisted upon which I didn't like, and added new features which I thought would be of benefit. Wherever possible I made each feature optional so that it could be turned on or off at will. I created a library of reusable modules to carry out such tasks as error handling, screen handling, text manipulation, date manipulation, etc, and made each routine easy to access with the aid of a separate COBOL macro (pre-compiler directive) which allowed the programmer to call any routine with a single statement in the source code. As well as making their job easier it also meant that some changes could be implemented simply by changing a single macro rather than dozens of programs. This development environment became the basis for all future projects undertaken by the company, and proved itself capable of being easily adapted to suit new requirements. When I left that company in 1999 some of the software which I wrote using that development environment was still being used by paying customers.
Over the years I added more features to the menu and security system and added to the library of subroutines and utility programs. At the end there were 20,000 lines of source code and seven volumes of documentation.
A big advantage of having a single set of standards integrated with a development environment was that there was only one set for the development staff to learn. They could therefore move from one project to the next with greater ease and be productive in a shorter time. It also meant that the time spent in setting up the development area for each new project was greatly reduced as a basic standard area already existed. Both of these points are valuable assets to a software house where time is money.
I knew that my development environment was pretty efficient, but it was not until I started getting favorable comments from outsiders that I realised that it was head and shoulders above any competition.
Eventually the amount of COBOL work began to dry up as customers wanted systems that were much more 'open'. As the American supplier of one of the software packages that we supported had just switched from COBOL to UNIFACE our company directors decided that it would be a good idea if we followed suit. The first two projects were in partnership with other companies - they did the design and set the standards, and we did the development. Unfortunately they had very little experience of a 4GL such as UNIFACE, and this was reflected in the poor quality of the work which they handed down to us. However, the exercise was not a total disaster as we came away from those projects with an enormous list of items labeled "Don't do it this way because....."
While I was busy on another task some of my colleagues decided to create their own standards for the next project. I thought that they had learned something after years of working with my 3GL standards, but sadly I was proved wrong. They got into the habit of making rules without first evaluating the options and choosing the best one. As soon as I started working in their development environment I couldn't help noticing how inefficient it was. In their attempts to design a new menu and security system they totally forgot about the KISS principle and produced something that was supposed to be clever but ended up by being clumsy.
Shortly afterwards I was given the task of creating a prototype payroll system which was required to incorporate some advanced features, so I decided that the first step was to create some decent standards and an efficient development environment. I continued my custom of finding out the quickest way to produce the best results, not just in the user's view of operability, but also from the programmer's view of maintainability. Unlike some of my colleagues who would often attempt to bend the language so that it would fit their design, I was willing to alter my design so that it would fit the language. You have to experiment with the language, find out its strengths and weaknesses, its capabilities and limitations, so that you can create a design that can be implemented efficiently. If your first design doesn't work out then change it and try again. You have to go with the grain, not against it. You have to swim with the current, not against it.
Just as I had done in my previous COBOL environment I identified repeating code and put it into reusable modules. I also redesigned and rebuilt the menu system to take advantage of the features that were available in the new language. In my labours I discovered that a lot of the principles which were valid in my old environment were still perfectly valid in this new one.
A prime example covers the scope of individual program modules (now called components) within a system. There is a choice between two extremes:
Too often I have heard it argued that the cost of development is directly proportional to the number of modules, so it was the done thing for many years to design a small number of modules and attempt to squeeze in as much functionality into each one as possible. I went along with this philosophy until I reached a point with one particular program when it became impossible to amend it further because it would no longer compile due to the huge amount of code. The only effective way to break it down into smaller pieces was to put all the code for each separate function (add, update, delete) into its own self-contained module. The advantages of small, simple components became immediately obvious - they are easier to design, easier to specify, easier to construct, easier to compile, easier to test, easier to document, easier to use, and easier to maintain. This helps to reduce the development effort without sacrificing quality, thus assisting in shorter delivery times and lower costs. Having seen for myself the benefits of small and simple components I will not willingly return to the old ways.
This subject is explored further in Component Design - Large and Complex vs. Small and Simple.
Another advantage to the small, single-purpose component comes to light when the user starts requesting additional security measures, such as restricting the different modes to different groups of users. If the different modes have been incorporated into a single component then additional code must be included to constantly compare what the user is attempting to do with what he is allowed to do. With a single mode component the rule is quite simple - either the user can access everything in the component or he can access nothing. If this is the case it makes sense to move the security checking out of the individual components into a single place, the menu system. If you have a dynamic menu system (like I do) then options which are not accessible to the user can be hidden from any menu screens, so if the user can't see an option he can't choose it.
An added security feature that is sometimes requested is the ability to restrict access to certain fields within a function. One way of achieving this is to make different versions of a screen each of which contains a different set of fields. However, this method involves a great deal of duplication which is something which we wish to avoid. UNIFACE has made this security option much easier to provide by supplying a function which dynamically turns off access to a field at run time. This makes the field and its associated label invisible, so the user cannot see or amend the value. All that is required is the ability to define a list of field names that the user cannot access, plus the code to process this list at run time. Both of these are provided in my development environment.
Being involved in the development of large numbers of components for several different systems I quickly noticed how similar some forms were to each other. They had the same arrangement of entities and the same behaviour, with the only difference being the actual entity and field names. It quickly became apparent that a quicker way to develop new forms was to take a copy of an existing form and then edit it manually to change the entity and field names. Over a period of time I found it useful to keep master copies of each type of form in a central place, which is where my example application was born. A document was then produced which described the structure and behaviour of each form so that the right master copy could be identified for a given set of requirements. This document has been incorporated into Part 1 of my development guidelines as the section on Dialog Types. This now contains over 50 entries.
This technique of basing new components on predefined examples received an enormous boost when UNIFACE version 7 was released with the facility for using component templates. Once I had figured out how to build and use them it became a simple step to create a component template out of each of the forms in my example system. I then rebuilt each form from the template just to verify that I had not missed anything out. Building a new form from a component template is much faster than the old copy, cut and paste method. It has the added advantage that changes to trigger code in a template can be automatically inherited by the components based on that template when they are next compiled. In order to make maximum use of this facility I put as much of my generic code as possible in local procs in form triggers. Now I can implement changes to a whole group of components just by changing one piece of source code in the template.
Just how much of a productivity boost are component templates? While working in UNIFACE 6 I had designed and built two prototype systems which took 12 weeks each. When I built a similar sized prototype in UNIFACE 7 it took just 6 weeks. This indicates that you can expect a 50% improvement!
This subject is explored further in The Power of Component Templates. When I later created a framework for web applications in the PHP language I managed to carry this idea forward and to create a library of Transaction Patterns.
When the ability to construct non-modal forms came out with v7 I was a bit skeptical until I actually saw what could be done with them. Coupled with the ability to pass messages from one component to another it quickly became clear that they could be extremely useful.
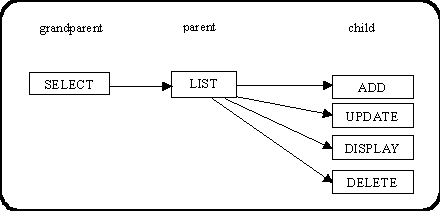
When I was experimenting with the code I quickly discovered two ways in which non-modal forms could be used. Using the family of forms in Figure 1 as an example this is what I found:
Figure 1 - A family of forms
From the LIST form the user selects the button which activates the ADD form. He can then return to the LIST form and activate the UPDATE form. This procedure can be repeated until all child forms have been activated. The user can switch focus from one form to another just by moving the cursor and clicking with the mouse. By using the messaging feature whenever one of the child forms is used to update the database it tells its parent (the LIST form) what it has done so it can update its display accordingly.
While playing with the UPDATE and DISPLAY forms it quickly became apparent that a useful feature would be to select an occurrence in the LIST form, select a child form (such as UPDATE or DISPLAY) then go back to the LIST form and select a different occurrence. This should cause the child form to refresh itself using the details from the newly selected occurrence, not the original one. It did not take very much effort for me to build this 'refresh' feature into my environment.
Another possibility then presented itself. Just supposing the user wanted to see two different instances of the same child form containing details from two different occurrences selected in the parent form? This would obviously conflict with the 'refresh' feature as by returning to the parent screen and selecting a different occurrence the first instance of the child form would be refreshed instead of allowing the user to create a new instance. Rather than building a system that would only cater for one of these options I decided to make it configurable - the user now has an option on the menu bar which will turn the refresh feature ON (allowing only one copy of each child form) or OFF (allowing multiple copies of each child form). This can be used while the system is running, so the user can switch from one option to the other as it suits him.
This subject is explored further in Some ways to use Non Modal forms.
My first contact with the idea of the 3 Tier software architecture, where presentation logic, business logic and data logic are separated out into 3 distinct layers or tiers, came when UNIFACE 7.2.04 was released. This provided the ability to take all database access and business logic out of the form and move it to a separate component known as an Object Service.
There were two aspects of Object Services which I really liked:
Each time the form executes an I/O command such as read or write or findkey UNIFACE will detect that an Object Service has been specified and will automatically redirect all I/O through that service. I decided to experiment with this new idea by modifying part of my sample application. However, after using it for a while I came across the following drawbacks:
The more I played with Object Services the more I realised that their use was too limited for sophisticated requirements, so I chose not to convert my whole development environment.
My second venture into the 3 Tier architecture came when I joined another software house and began work on a project for a government department. Here they introduced an additional twist - a separate application model for the presentation layer. I thought this idea was a bit strange at first, but after some research I began to be convinced of its advantages.
However, having fancy ideas is one thing, but if you can't implement them effectively and efficiently then they aren't worth much. They had a team of 6 people who spent 6 months designing and building the infrastructure, and when it came to build the first Use Case - a screen into which selection criteria could be entered, followed by a screen which listed the occurrences which matched that criteria - I was astounded at how long it took. They had 6 people working on it, and it took 2 weeks! That's 60 man-days! I had built similar Use Cases in UNIFACE 7 many times using my own infrastructure, and times as low as 60 minutes were quite common.
I thought their infrastructure was unworkable, and I stood up and said so at the next project meeting. I was shouted down with cries of "Your methods are old fashioned" and "These are the methods of the future". But try as they might they could not get the development times down to acceptable levels, so it came as no surprise when the client cancelled the whole project. Well, what would you do if you were told that the project was going to be 6 months late and £2 million over budget?
When it was recognised that the development infrastructure was unworkable they tried to look for ways to save the project by looking for an alternative infrastructure. They eventually decided to have a look at what I had to offer and they were impressed with the speed at which I could build working components. They decided to see how easy it was for one of the other developers to use my development environment, so they arranged to have a part of their system rebuilt using my techniques. I was only allowed to give him 30 minutes instruction, but even this brief training enabled him to take a Use Case that had previously taken 10 days and rebuild it in 10 hours.
However, my environment was deemed to be unacceptable because it used 2 Tiers in its architecture instead of the fashionable 3. The fact that it worked was irrelevant, it was not 'politically correct'. More details of this disaster can be found at UNIFACE and the N-Tier Architecture.
At this time UNIFACE version 7.2.06 was released. When I read the release notes regarding the new instructions for manipulating XML streams I immediately saw that it was a far superior method of implementing the 3-Tier architecture than the one devised by the architects of my previous project.
I took some sample components in my 2-Tier development environment and within 2 weeks I had successfully converted them to 3-Tier. All the presentation layer components access a separate application model which is not connected to the database. Only the service components in the business layer actually access the physical database. It is also in the business layer that all data validation is performed. The communication of data between the presentation and business layers is achieved by the passing of XML streams. Because this method uses what are known as 'disconnected record sets' it can be used for both client/server and web applications. The results are available on my website in a document called '3 Tiers, 2 Models, and XML Streams' where you can also download my sample code.
I have also converted my entire demonstration application from 2 tier to 3 tier, and both versions can be downloaded from my Building Blocks page.
Not too long ago I went to a company who regarded themselves as "innovators" in the world of UNIFACE development. They were particularly proud of the fact that they had built their software using the 3 tier architecture, but when I looked at how it was built I was aghast. Instead of allowing the developers to use the most efficient methods of achieving results their standards seemed to be deliberately designed to force the developer to take the most round-about and error-prone route. To top it all they seemed to be completely unaware that UNIFACE was already built around the 2 tier architecture with its interchangeable database drivers in the data access layer, so they actually had a 4th layer which achieved absolutely nothing apart from adding to the burden of development and maintenance.
I wrote a 17 page 9,000 word document which identified all the areas where they could improve their development techniques. When I presented it to them they were shocked that somebody had the balls to call their standards rubbish, and doubly shocked that I had the ability to prove it by showing them what I could do with my own development environment which I just happened to have on my personal laptop. I took one of the components for which they had given an estimate of 1½ days and built it in less than 1 hour. If you do the maths you will see that I produced a result not 10% faster but 10 times faster. Not an insignificant improvement, wouldn't you say?
Edited highlights of my findings an be found in How not to implement the 3 Tier architecture in UNIFACE.
My first attempt at the development of a web application was a total disaster. One simple fact that I learned from this failure was that if I wanted to branch out into web development then UNIFACE was totally the wrong language. In the first place it was proprietary and way too expensive, and in the second place it was too clunky. Having seen how much effort was involved in generating an HTML document and dealing with each incoming request I knew there just had to be a better way. Rather than wait for my employer to teach me any new skills I decided, in the middle of 2002, to teach myself in my own time. As I already had my own PC at home it was a simple matter to download everything I needed - the Apache web server, the PHP language and the MySQL database (all for free!) - and get to work.
I bought some books in order to learn the fundamentals of the new language, and once I had found out how to do the the basics I started work on converting my UNIFACE framework (which was converted from my COBOL framework) into PHP. My starting point was as follows:
After reading a few OO tutorials I quickly formed the opinion that their approach was totally out of step with my ideas on how software should be written, so I chose to ignore everything I read from these so-called "experts" and do my own thing. This was a decision that I have NEVER regretted. Among the things which I do improperly (according to the "paradigm police") are:
$this->fieldarray['column']as it is a dedicated variable, as in:
$this->column
The fact that I pass volumes of data around in a single array instead of separate variables means that I can create components which have a higher level of reusability. For example, if I have a presentation layer component which performs an operation on a database table, but neither the table name nor any of the column names are hard-coded into that component, then it is obvious that the component needs no alterations before it can perform the same operation on a different database table with different column names. Similarly I can have a single function which can extract the data array from any business object and convert it into an XML document without the function having any hard-coded table or column names. This then allowed me to create a series of presentation layer components which could each perform a certain operation on an unknown database table, then convert the results into an XML document which could be transformed into HTML using an unknown XSL stylesheet.
This leaves me with the situation where I have a component which performs a specific operation on an unknown database table and transforms the result using an unknown XSL stylesheet. This is easy to solve - have a script which loads the identities of the database table name and XSL stylesheet name into variables, then pass control to a separate script which performs its processing using those variables. This results in what I call a component script which is as simple as the following:
<?php $table_id = "person"; // table id $screen = 'person.detail.screen.inc'; // file identifying screen structure require 'std.enquire1.inc'; // activate controller ?>
The $table_id variable is used to identify the file which contains the class definition from which an object can be instantiated to deal with that database table.
The $screen variable is used to identify the file which contains the name of the XSL stylesheet which is to be used in the transformation, plus a list of column names which will appear in the HTML output.
The require statement passes control to the standard code which performs the "enquire" operation. I call this a "controller" as it forms the "controller" part of the Model-View-Controller (MVC) design pattern. This contains code similar to the following:
require "classes.$table_id.class.inc"; $dbobject = new $table_id; $data = $dbobject->getData($where);
As you can see the controller does not contain any hard-coded table names, and it can handle any data which the object returns without any hard-coded column names. This means that the controller can perform its operation on ANY database table with ANY NUMBER of columns, which increases the re-usability to an enormous degree. This is in total contrast to examples I came across in some of the tutorials where there was a separate copy of each controller for each database table as both the table and column names had to be hard-coded. Where is the re-usability in that?
When it came to building my business and data access layers I did not do what most OO programmers are taught, which is to start with a design that conforms to some abstract rules, then to write the code which conforms to that design. My reasoning was simple - I did not agree with those abstract rules as they placed arbitrary restrictions on how I could achieve the expected result. I am results-oriented, not rules-oriented, so I will make or break as many rules as I like in order to achieve the expected result. My method was extremely simple:
A common method of sharing code in a object oriented language is through inheritance, so I put all the common code into an abstract table class so that every database table class could inherit from it. This resulted in an abstract table class which was very large, and a collection of individual database table classes which were incredibly small, consisting of no more than the following:
<?php require_once 'std.table.class.inc'; class #tablename# extends Default_Table { function #tablename# () { // save directory name of current script $this->dirname = dirname(__file__); $this->dbms_engine = $GLOBALS['dbms']; $this->dbname = '#dbname#'; $this->tablename = '#tablename#'; // call this method to get original field specifications $this->fieldspec = $this->getFieldSpec_original(); } // #tablename# // **************************************************************************** } // end class // **************************************************************************** ?>
As you can see I have isolated the differences between one database table and another to no more than the following:
The field specifications are actually held in a separate file so that they can be replaced without having to overwrite the class file which may have been modified to include any custom code. The file of field specifications can be replaced at any time to keep it synchronised with the table's structure. It's contents are similar to the following:
<?php // file created on May 30, 2005, 10:45 am // field specifications for table dbname.tblname $fieldspec['fieldname1'] = array('keyword1' => 'value1', 'keyword2' => 'value2'); $fieldspec['fieldname2'] = array('keyword1' => 'value1', 'keyword2' => 'value2'); // primary key details $this->primary_key = array('field1','field2'); // unique key details $this->unique_keys[] = array('field1','field2'); $this->unique_keys[] = array('field3','field4'); // child relationship details $this->child_relations[] = array('keyword1' => 'value1', 'keyword2' => 'value2'); $this->child_relations[] = array(...); // parent relationship details $this->parent_relations[] = array('keyword1' => 'value1', 'keyword2' => 'value2'); $this->parent_relations[] = array(...); // determines if database updates are recorded in an audit log $this->audit_logging = TRUE/FALSE; // default sort sequence $this->default_orderby = 'fieldname1,fieldname2,...'; // finished ?>
The contents of this file are explained in more detail here.
What is a pattern? I use the following definition:
A pattern is a recurring theme, or something from which copies can easily be made.
While a large number of OO programmers are aware of things called "design patterns", this is simply because they are regularly told by their peers that they are a "good thing" and should be used whenever and wherever possible. Unfortunately these programmers do not seem to know how to apply these patterns intelligently - instead of asking "I have this problem, which pattern could I use to solve it?" they ask "I have read about this cool pattern, how can I implement it to show how clever I am?" Like a lot of things in this life which can be used, they can also be mis-used or even ab-used. The use of design patterns does not guarantee success - it is possible to use the wrong pattern in a particular situation, or even to implement that pattern badly. A design pattern, after all, is not a block of pre-written code, it is simply a design for a block of code which has to be written. This means that the same pattern can be implemented in different languages, but it also means that even in the same language different programmers can (and often will) write different code. That code can be good, but it can also be not so good. It is therefore possible to use the right pattern but the wrong implementation.
I do not use design patterns. By this I mean that I do not "consciously" use design patterns. I do not read about them and then try to implement them in my code. I simply write code, and if I happen to write something which conforms to a particular pattern then that is by coincidence and not by design. This is what happened with my implementation of The Model-View-Controller (MVC) Design Pattern for PHP - I did not read about the pattern and try to implement it, I simply wrote the code and discovered later that it matched the description of that pattern.
I do not produce web sites, I write database applications which are often called CRUD applications based on the fact that they revolve around the four basic operations which can be performed on a database table - Create, Read, Update and Delete. I was building these applications before the web was invented, but have now learned how to build them so that they can be deployed over the web. This type of application is built to be used by businesses and contains a number of components known as "transactions". These are based on business transactions and are not to be confused with database transactions. A "business transaction" is a unit of work from a business perspective whereas a "database transaction" is nothing more than a collection of database updates which may be the result of a business transaction. A business transaction is bigger than, but may contain, a database transaction.
A computer application is made up of a collection of components which help the user to conduct his day-to-day business. These components can be called "transactions" because they are closely related to business transactions. Some of these may not involve database transactions for the simple reason that they do not update the database. Querying the database does not update it, but a component still has to be written so that the user can view the data.
A software application may have a database which contains many tables, and each table will probably need its own set of components to view and manipulate its data. Anyone who develops large numbers of these components will quickly realise that it is not necessary to write each new component from scratch but to copy an existing component and modify it so that it does exactly the same thing but for a different database table. By identifying that there is something in an existing component which can be reused in a new component you have automatically identified a recurring theme, a pattern. In a large application it may be possible to identify a number of such patterns, some of which may repeat more often than others.
Some people see to have difficulty in identifying what parts of a transaction can possibly repeat and thereby form a pattern, so for those of you who are intellectually challenged I'll give you a clue - If you look closely at the screen used by any transaction you should be able to identify the following characteristics:
| STRUCTURE | How many different areas or zones does the screen have? Do they contain different sets of buttons or different pieces of data, or have different functions? Is there data from a single database row where each column has its own label, or are there multiple database rows which are arranged horizontally with column labels at the top? |
| BEHAVIOUR | Is it read-only, or can the database be modified? Does the screen start as empty, or is it pre-filled with data? You should see that if you have separate transactions for each of the create, read, update and delete operations then each of them has different behaviour. |
| CONTENT | Which columns from how many database tables are being displayed and/or manipulated. |
With these characteristics it is possible to have transactions with the following combinations:
Being able to identify a pattern is only the first step. The next problem is to find a means by which new copies of that pattern can be implemented, and this may be difficult or easy depending on which language you are using. Some languages may have a "pattern implementor" built in, while in others you will have to create your own. In COBOL, my first language, there was no such mechanism so we resorted to copying the source code for an existing component, then laboriously edited it line by line to change all references of 'table-A' to 'table-B' and 'column-A' to 'column-B'. This may have been hard work, but it was still less work than creating a new component completely from scratch. Some people, mainly those who have never used COBOL at all, or only briefly, complain that it is too verbose, that it requires a lot of code to do relatively simple things. This may be true, but the wise COBOL programmer will reply that it is necessary only to write your first program from scratch, while all others are nothing more than modified copies.
In my next language, an obscure product called UNIFACE, was a facility called component templates which allowed a pattern to be defined in such a way that it became possible to build a new component simply by saying "implement this pattern on that entity". Although it still required some work to define the layout of the screen it was a big step forward. After creating my own set of patterns I discovered that I could build new components in half the time, so they were a great boost to productivity. Unfortunately I found that very few other people could achieve the same productivity gains though the use of component templates. Most simply did not recognise any patterns from which templates could be built, while a few built templates which were virtually useless. One organisation I joined (only briefly) were proud of the fact that they had 5 component templates, and laughed when I told them that I had 50. Those comedians failed to realise that although they only had 5 templates what they actually needed was 50. Their 5 templates were so primitive that it required a great deal of effort to create a final working component, so much so that they were ignored by the developers in favour of the age-old technique of finding an existing component, copying it, then modifying it. Each of my 50 templates was highly specialised, with the only difficulty being to identify which template, or group of templates, to utilise in a particular set of circumstances.
When I decided to move into web development my first decision was to ditch UNIFACE for PHP, then to rebuild my UNIFACE framework (which was actually a rewrite of my previous COBOL framework) in this new language. There were several practices from my UNIFACE framework which I decided to carry forward into PHP if at all possible:
Knowing what I wanted to achieve it was then a relatively straightforward matter to write the code to achieve it. This was done with the following components:
Having previously used the concepts of structure, behaviour and content to categorise each transaction I eventually ended up with the following components from which I could build transactions:
| STRUCTURE | A separate XSL stylesheet for each different screen structure. My library contains 12 reusable stylesheets. |
| BEHAVIOUR | A separate page controller which performs a particular set of operations on a database object using a particular XSL stylesheet. My library contains 38 reusable controllers. |
| CONTENT | A separate class/object for each table in the application database. All the code which is common to any database table is defined in and inherited from a superclass. Thus the class for a specific database table contains only the code which is unique to that database table. |
The page controller receives HTTP requests, performs certain operations on a database object and transfers the results into an XML document which are transformed into an HTML response using an XSL stylesheet.
The physical I/O with a particular database engine (MySQL, PostgreSQL, Oracle, etc) is carried out in a separate Data Access Object (DAO), which makes it easy to switch from one DBMS to another.
I eventually ended up with a separate page controller for each transaction pattern. Each page controller uses a single XSL stylesheet, with some stylesheets being shared by multiple controllers. I made each page controller reusable so that it could operate on any table class in the system without modification. To create an individual component all I had to do was create a small script which identified what controller to use on what database class. Initially I created these by hand, but later I modified my data dictionary to generate them automatically.
I have now reached the point where I can create a database table, import it into my data dictionary at the touch of a button, then generate the transactions to view and manipulate the contents of that database table at the touch of another button. All I have to do is say "use this pattern on that database table" and a fully functional transaction is available for immediate use. Not only do I not have to write any SQL or HTML, I don't even have to write any PHP code either!
Some people try to tell me that transaction patterns do not exist for the simple reason that they haven't read about them in any books. This just proves that they are nothing more than code monkeys who wouldn't recognise a pattern even if it crawled up their legs and bit them in the a**e. Not only do transaction patterns exist, but it is possible to build an entire application where every single component is built from a pattern. Couple this with a "pattern implementor", a mechanism by which a new component can be quickly generated from a pattern, and you have a tool which could see your productivity accelerate into overdrive. Using the Radicore framework I was able to build an application containing 130 database tables, 230 relationships and 1000 tasks in just 6 months. All from 12 XSL stylesheets and 38 page controllers. Can you beat that?
Here are some references to other articles I have produced which are based upon my experiences:
Tony Marston
30th April, 2001
mailto:tony@tonymarston.net
http://www.tonymarston.net
| 24th June 2008 | Added Another new language and Transaction Patterns. |
| 22nd Sept 2003 | Added Case #2, Case #3, Case #4 and Somebody else's 3 Tier architecture. |
| 10th June 2002 | Added links to other documents I have written. |