Methodology Overview
Here is a list of the main points in this particular methodology:
- The Business Application Model (BAM) defines the physical database and is used by components in the business layer. These have the standard I/O commands in the <read>, <write>, and <delete> triggers.
- The Presentation Application Model (PAM) is not connected to any physical database and is used by components in the presentation layer. These have the standard I/O commands removed from the <read>, <write>, and <delete> triggers.
- All Document Type Definitions (DTDs) are defined in the PAM using entity and field names defined within the PAM, therefore PAM components should not require any mapping options.
- All mapping between PAM entities and BAM entities will be performed by session service components in the business layer.
- Generally each PAM entity will have a single DTD which will have the same name as the entity. This makes it easier for the generic software to identify which DTD to use for that entity. An entity may not have a DTD if it is included in the DTD for another entity.
- It is possible for an XML stream to contain data for more than one entity, but this will be built from a single DTD which will be named after the most significant entity.
- Although it is possible to construct DTDs from component definitions in this methodology they are constructed from entity definitions. Each entity will have its own DTD and its own session service, which means that if several components refer to the same entity they can share the same DTD and the same session service.
- It is possible for a component to contain several entities which have separate DTDs. In this case the data for those entities will have to be processed in separate operations.
- Some fields in the XML stream, such as those obtained from foreign entities, are optional and will not be retrieved unless required. The generic software identifies the fields that are required by the presentation layer component by using the
$SELECTLIST function. For this to work the fields in the PAM entity cannot have their characteristics set to Non-database.
- For each entity in the PAM the identity of the associated session service will be defined in the entity properties as the Object Service Name. The generic software can thus identify which session service to use for that entity by using the
$ENTINFO function. For this to work the PAM entity cannot have its DBMS path set to Not in database.
- All data validation will be defined within the business layer, not the presentation layer.
- When a presentation layer component has data that it wants validated it must activate an operation on a session service in the business layer. The data to be validated will be passed in an XML stream as a parameter on that operation.
- Operations exist which will allow this data validation to be performed at the <validate field>, <validate key>, <validate occurrence> as well as the <store> stages.
- All presentation layer components should be built from component templates as these already contain the necessary proc code to exchange data with the business layer.
- All session services should be built from component templates as these already contain the operations which are necessary to service the requirements of the presentation layer.
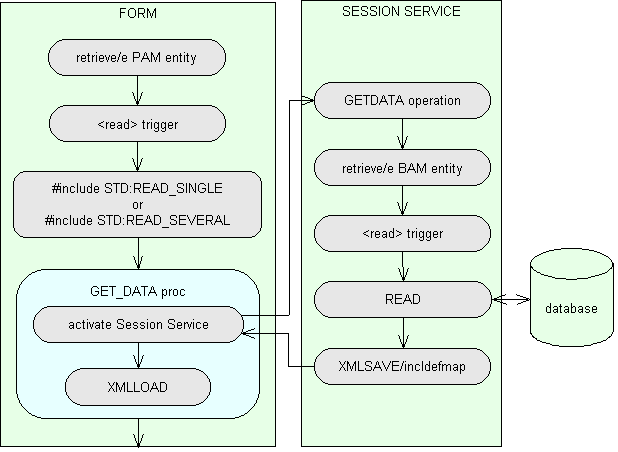
- When a presentation layer component requires data is does not read directly from the database - instead it will activate the GETDATA operation on a session service. This is handled by the global proc GET_DATA. This proc is used on an entity which must have a DTD available with the same name.
- If the DTD contains additional entities then the data for these entities will be supplied in the XML stream along with the data for the primary entity. These additional entities will not require their own DTDs unless they are to be processed independently.
- There are no stepped hitlists with XML streams as all the data is obtained from a single activation of the session service. If the number of occurrences needs to be restricted then it is possible to use the maxhits option which is available on the
read command in the session service. Each presentation layer component must have a $MAXHITS$ component variable which can be used to supply this value.
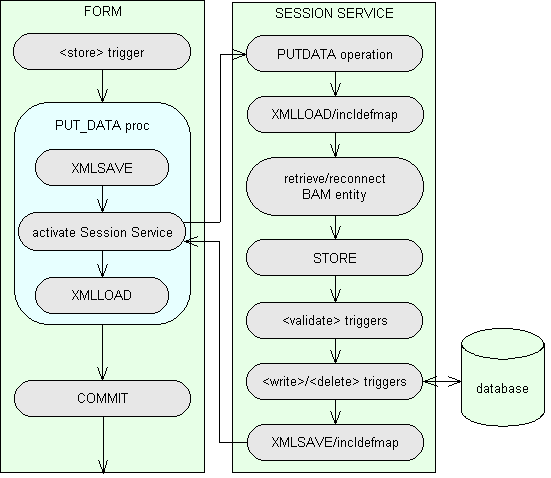
- When a presentation layer component wants to write data is does not go directly to the database - instead it will activate the PUTDATA operation on a session service. This is handled by the global proc PUT_DATA which is used in the <store> trigger instead of the
STORE command.
- In order to test for a database occurrence in a presentation layer component the function
$DBOCC cannot be used as the occurrence is not connected to the database. You must use $OCCSTATUS = "est" instead, which relies on the processing information being present in the XML stream.
Method: call GET_DATA(entname, orderby, options)
| Where: |
entname | is in the format 'entity.model' |
| |
orderby | is in the format used by the orderby clause on the read command. |
| |
options | is in the format used by the options clause on the read command. |
- Constructs the DTD name as 'DTD:entity.model'.
- Uses
$SELECTLIST to construct a list of fields to be returned.
- Constructs a retrieve profile using values from the current occurrence of
entname.
- Uses
$ENTINFO to obtain the name of the session service from the Object Service value in the entity's properties.
- Activates the GETDATA operation on the session service, which returns an XML stream and the hit count for the main entity.
- Loads the contents of the XML stream into the component's structure using the
XMLLOAD command.
- The count of hits for
entname is returned in $STATUS.
Method: activate service.GETDATA(profile, selectlist, orderby, options, xmlstream)
| Where: |
profile | is used as the profile when retrieving occurrences from the BAM entity. |
| |
selectlist | is an indexed list of field names to be included in the output XML stream. |
| |
orderby | is an indexed list of field names to be used as the sort sequence on the read command. |
| |
options | is an associative list of options for the read command. Currently only the maxhits=n option is used. |
| |
xmlstream | returns all the data retrieved by the session service. |
- Constructs the DTD name as 'DTD:entity.model'.
- Sets the MAXHITS option in the
$OPTIONS$ variable.
- Copies the retrieve profile to the PAM entity using
GETLISTITEMS/occ.
- Saves this into a temporary XML stream using
XMLSAVE/one.
- Loads the XML stream into the BAM entity using
XMLLOAD/incldefmap to convert any field names.
- Retrieves the BAM entity using the
$OPTIONS$ and $ORDER_BY$ variables. There is no stepped hitlist with XML streams, so all available occurrences will be retrieved (up to the value for maxhits, if supplied).
- Data from foreign entities is only retrieved if the field names are included in
selectlist.
- Saves the contents of the component's structure into an XML stream using
XMLSAVE/incldefmap. This is returned to the calling component, along with the hit count in $STATUS.
Method: call PUT_DATA(entname)
| Where: |
entname | is in the format 'entity.model' |
- Constructs the DTD name as 'DTD:entity.model'.
- Uses
$ENTINFO to obtain the name of the session service from the Object Service value in the entity's properties.
- Saves the contents of the component's structure into an XML stream using the
XMLSAVE command. By default this will only include those occurrences which have been modified, but you can force the proc to include all occurrences by setting global variable $$XMLSAVE_ALL to TRUE.
- Activates the PUTDATA operation on the session service, which returns an XML stream with the results of the
STORE command.
- If the operation is successful then a
COMMIT is issued.
Method: activate service.PUTDATA(xmlstream)
| Where: |
xmlstream | contains the data which is obtained from and returned to the presentation layer component, |
- Constructs the DTD name as 'DTD:entity.model'.
- Loads the contents of the XML stream into the component's structure using
XMLLOAD/incldefmap.
- Validates any occurrences which are marked for deletion by checking for the existence of occurrences on subordinate entities.
- Issues the
RETRIEVE/reconnect command to reconnect any disconnected occurrences to the database.
- Issues the
STORE command (without a COMMIT) to perform validation and update the database.
- Saves the contents of the component's structure into an XML stream
XMLSAVE/incldefmap. This is returned to the calling component in case any fields have been modified, such as technical keys which are only generated at the STORE stage.
The <read> trigger in each PAM entity should not contain the read command as the entity does not exist in any database. By default this trigger should contain the statement #include STD:READ_TRIGGER which takes care of this when compiled in a presentation layer component.
However, in my presentation layer components I still use the retrieve/e command to obtain data, so the contents of the <read> trigger for that entity needs to be changed to one of the following statements:
#include STD:READ_SINGLE - retrieve a single occurrence- This is equivalent to a
retrieve/x statement in that it expects to retrieve a single occurrence, usually by its primary key. It will call the GET_DATA proc setting maxhits=1 and orderby="", and will error if no retrieve profile is provided. It will also error if more than 1 occurrence is retrieved. If a single occurrence is successfully retrieved it will automatically fire the <read> trigger of any inner entities defined within the component.
#include STD:READ_SEVERAL - retrieve any number of occurrences- This is equivalent to a
retrieve/e or retrieve/a statement in that it will retrieve all those occurrences which match whatever retrieve profile has been supplied, including a null profile. It will call the GET_DATA proc setting maxhits=$MAXHITS$ and orderby=$ORDER_BY$. If occurrences from previous retrieve operations exist in the component then the results of the current retrieve will be appended to the existing contents and duplicate entries removed. This is similar to the standard processing for the retrieve/a command.
This results in a process flow diagram as shown in figure 1:
Figure 1 - how a presentation layer component receives data
The <store> trigger for the component is inherited from the component template, so no further action need be taken. Instead of a STORE command this contains a call to the PUT_DATA proc, followed by a COMMIT or ROLLBACK as necessary.
If a STORE command were to be issued it would have no effect as the <write> and <delete> triggers of all the entities do not contain any code.
This results in a process flow diagram as shown in figure 2:
Figure 2 - how a presentation layer component stores data
Validation at various levels is available provided that the following proc statements are inserted into the relevant triggers:
#include STD:LMK_TRIGGER - <leave modified key> trigger- This uses the
RETRIEVE/O command to perform standard processing when leaving a key field which has been modified.
#include STD:VLDK_TRIGGER - <validate key> trigger- This will create an XML stream for the current occurrence using
XMLSAVE/one, then activate the VALIDATEKEY operation on the session service in order to perform any validation for the current key.
#include STD:VLDO_TRIGGER - <validate occurrence> trigger- This will create an XML stream for the current occurrence using
XMLSAVE/one, then activate the VALIDATE operation on the session service in order to perform any validation on the whole of this occurrence. If any fields are modified during this validation they are passed back in an associative list so that they can replace the current values.
#include STD:VLDF_TRIGGER - <validate field> trigger- This will create an XML stream for the current occurrence using
XMLSAVE/one, then activate the VALIDATE operation on the session service in order to perform any validation for the current field only. If any fields are modified during this validation they are passed back in an associative list so that they can replace the current values.
call VERIFY_DELETE("entity") - <detail> or <exec> trigger- This will create an XML stream for the current occurrence using
XMLSAVE/one, then activate the VERIFY_DELETE operation on the session service in order to check that it is safe to be deleted. If any occurrences exist on subordinate entities which are named in the local proc LP_DONT_DELETE then a negative status is returned.



